强化学习(DQN)教程REINFORCEMENT LEARNING (DQN) TUTORIAL
PyTorch 强化学习 01.强化学习(DQN)
本教程介绍如何使用PyTorch从OpenAI Gym中的 CartPole-v0 任务上训练一个Deep Q Learning (DQN) 代理。 1.任务 代理人必须在两个动作之间做出决定 – 向左或向右移动推车 – 以使连接到它的杆保持直立。您可以在Gym 网站上找到官方排行榜,里面包含各种算法以及可视化。 当代理观察环境的当前状态并选择动作时,环境转换到新状态
使用gym库Classic control实现deep Q learning
://blog.csdn.net/cs123951/article/details/77854453 MountainCar原理参考 OpenAI gym提供了强化学习时的环境模块,使得我们实现强化学习算法的时候无需关注于模拟环境的实现。 CartPole实例 运载体在一根杆子下无摩擦的跟踪。系统通过施加+1和-1推动运载体。杆子的摇摆在初始时垂直的,目标是阻止它掉落运载体。每一步杆子保持垂直可以获得+1的奖励
使用DDPG算法实现cartpole 100万次不倒
.com/envs/CartPole-v0/ 这个网站提供的一个杆子不倒的测试环境。 CartPole环境返回一个状态包括位置、加速度、杆子垂直夹角和角加速度。玩家控制左右两个方向使杆子不倒。杆子倒了或超出...动作的内存也是7500行容量。 创建Brain_DDPG为agent。 在每个回合的步骤中,从agent获得动作,并加入正确分布的随机值。随机值的系数在训练后逐步减少直至为0. 从环境获得奖励和下一个
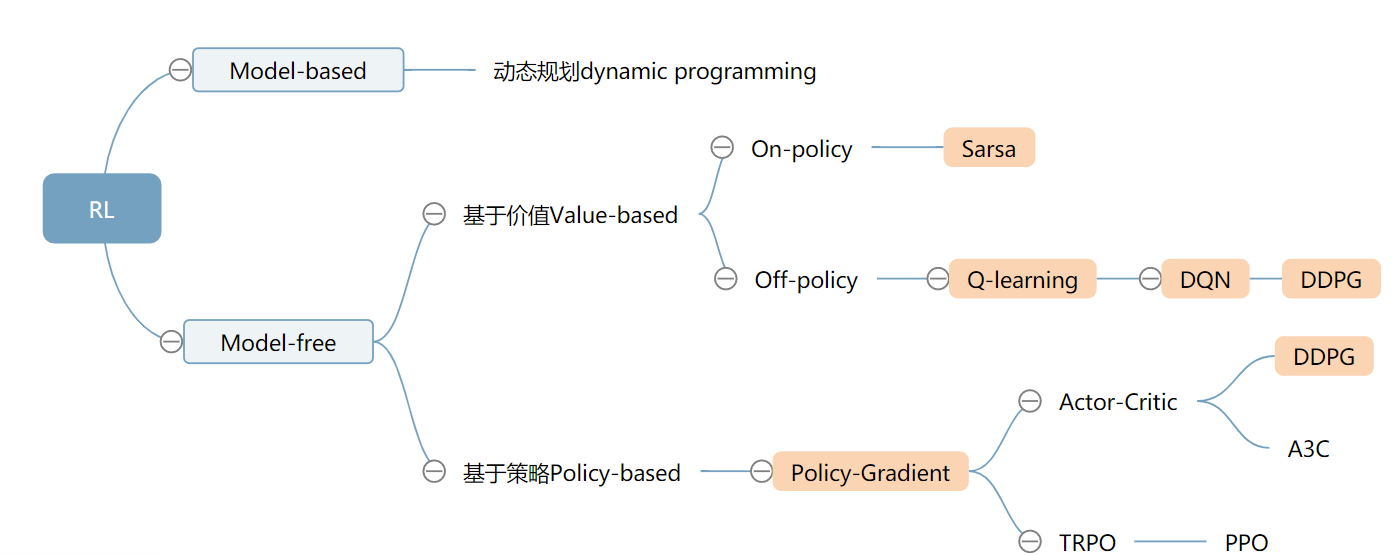
强化学习七天打卡营学习笔记
场景】 3. DQN简介 上节课介绍的表格型方法存储的状态数量有限,当面对围棋或机器人控制这类有数不清的状态的环境时,表格型方法在存储和查找效率上都受局限,DQN的提出解决了这一局限,使用神经网络来近似替代Q表格。 本质上DQN还是一个Q-learning算法,更新方式一致。为了更好的探索环境,同样的也采用ε-greedy方法训练。 在Q-learning的基础上,DQN提出了两个
智能推荐
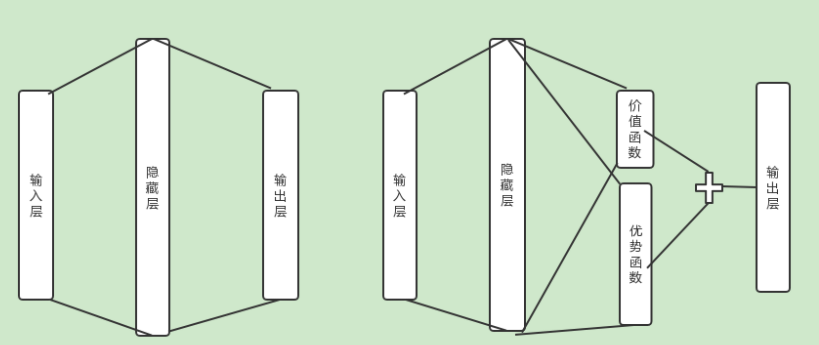
强化学习的学习之路(二十一)_2021-01-21: Dueling DQN(Dueling networkarchitectures for deep reinforcement learning)
作为一个新手,写这个教程也是想和大家分享一下自己学习强化学习的心路历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己能保证起码平均一天一更的速度,先是介绍强化学习的一些基础知识,后面介绍强化学习的相关论文。本来是想每一篇多更新一点内容的,后面想着大家看CSDN的话可能还是喜欢短一点的文章,就把很多拆分开来了,目录我单独放在一篇单独的博客里面了。完整的我整理好了会放在github上,大家一...
强化学习——从Q-Learning到DQN到底发生了什么?
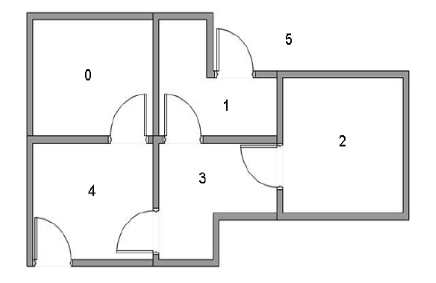
1 学习目标 1. 复习Q-Learning; 2. 理解什么是值函数近似(Function Approximation); 3. 理解什么是DQN,弄清它和Q-Learning的区别是什么。 2 用Q-Learning解决经典迷宫问题 现有一个5房间的房子,如图1所示,房间与房间之间通过门连接,编号0到4,5号是房子外边,即我们的终点。我们将agent随机放在任一房间内,每打开一个房门返回一个r...
强化学习 7—— 一文读懂 Deep Q-Learning(DQN)算法
上篇文章强化学习——状态价值函数逼近介绍了价值函数逼近(Value Function Approximation,VFA)的理论,本篇文章介绍大名鼎鼎的DQN算法。DQN算法是 DeepMind 团队在2015年提出的算法,对于强化学习训练苦难问题,其开创性的提出了两个解决办法,在atari游戏上都有不俗的表现。论文发表在了 Nature 上,此后的一些DQN相关算法都是在...

强化学习(reforcement learning)之Deep Q-network(DQN)算法简介
Deep Q-network(DQN)是一项实用度很高的强化学习算法,下面进行一个简介,后期还会持续更新。 这个是DQN的一个算法伪代码表示: 首先初始化,我们初始化2个网络:Q 和Q^,其实Q^就等于Q。一开始Q^这个目标 Q 网络,跟我们原来的Q网络是一样的。在每一个episode(回合),我们用actor(演员)去跟环境做交互,在每一次交互过程中,我们都会得到一个状态st...

强化学习——DQN算法
Off-Policy:会记忆之前的经验,依据经验做决策。 Experience replay:记忆库(用于重复学习) Fixed Q-targets:暂时冻结q_target函数(切断相关性) 这里边的q_target就是Q现实 两个神经网络是为了固定住一个神经网络 (target_net) 的参数, target_net 是 eval_net的一个历史版本, 拥有&...
猜你喜欢

强化学习与DQN
在Q-learning中很重要的一点,是要去预估未来收益,所以在离散情况下,一般用的是table-based Q-learning算法。它会给出一张表,不断去迭代,直到这张表收敛稳定。当状态空间太大,例如围棋和游戏,就要用深度神经网络。 强化学习存在的两点问题: 1.信用分配问题(credit assignment problem) 击中砖块并且得分和前一时刻如何移动横杆没有直接关系;前面某一时刻...
强化学习DQN算法
DQN,即Deep Q-learning算法,是将神经网络与Q-learning算法相结合而得到的强化学习算法。在DeepMind发表的论文《Playing Atari with Deep Reinforcement Learning》(https://arxiv.org/abs/1312.5602)中,DeepMind使用DQN算法训练出可以玩Atari游戏的模型,该模型甚至在某些游戏上表现的比...

强化学习之DQN
参考:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ DQN的两大特色: Experience replay:经验回放,Q-learning是一种off-policy离线学习方法,可以利用以前的经验进行学习 Fixed Q-targets:打乱相关性,用到两个结构相同,但架构不同的神经网...
自定义类加载器
自定义类加载器 我们如果需要自定义类加载器,只需要继承ClassLoader类,并覆盖掉findClass方法即可。 自定义文件类加载器 自定义网络类加载器 热部署类加载器 当我们调用loadClass方法加载类时,会采用双亲委派模式,即如果类已经被加载,就从缓存中获取,不会重新加载。如果同一个class被同一个类加载器多次加载,则会报错。因此,我们要实现热...
用户界面和兼容性测试
用户界面测试 1 、导航测试 导航直观 Web系统的主要部分可通过主页存取 Web系统不需要站点地图、搜索引擎或其他的导航帮助 Web应用系统的页面结构、导航、菜单、连接的风格一致 2 、图形测试 图形有明确的用途 所有页面字体的风格一致。 背景颜色与字体颜色和前景颜色相搭配。 图片的大小减小到 30k 以下 文字回绕正确 3 、内容测试 Web应用系统提供的信息是正确的 信息无语法或拼写错误 可...
问答精选
How we can create Dataproc cluster through rest API or http request?
I am new in python, Here I want to create dataproc cluster using http request. I am following below dataproc documentation where they mentioned in REST API section. see below https://cloud.google.com/...
AddWithValue method on ASP.NET
I am using AddStringWithValue method in ASP.NET using C# My HTML code is My C# code for the method is: The problem is, it is giving red underline under email and password. Shouldn't we identify them w...
How to apply css using a condition?
I'm trying to apply this css: this works well, the problem is that the web app can set a class on the body called white-content, if the white-content class is setted, then I can't see the text of h2, ...
Tile game collision detection with sprite moving to arbitary (x,y)
So I am struggling with some logic for collision detection in my game. I have a grid of tiles(images), all representative of a value in a 2D array, so the location of tile N would be (column m, row n)...
Kotin sort by descending then ascending
Im trying to order a list on multiple parameters.. for example, one value descending, second value ascending, third value descending. is there a way like this to do it? (i know is incorrect) people = ...
相关问题
- 交易算法 - Q学习/DQN中的动作
- 如果A大于B,请求解DQN
- 强化学习:在Q-Learning完成后,我必须忽略Hyper参数(?)吗?
- 学习与DQN一起玩曲线发烧游戏的奖励功能
- 为什么我的DQN在Breakout V0上的代理商不学习?
- Learning the Structure of a Hierarchical Reinforcement Task
- 我的2048年游戏的双DQN算法永远不会学到
- What are the uses of recurrent neural networks when using them with Reinforcement Learning?
- 为什么DQN会为所有观测值提供与动作空间中所有动作(2)中的所有动作相似的值
- 在神经网络中的Q-Learning不是'学习'
相关文章
- 【强化学习】DQN(Deep reinforcement learning) Basic
- 从强化学习Reinforcement Learning到DQN(Deep Q-learning Network)学习笔记
- 深度强化学习5——Deep Q-Learning(DQN)
- 入门强化学习(Q-learning→DQN→DDQN)
- 强化学习-DQN
- DQN
- DQN
- [DQN] Playing Atari with Deep Reinforcement Learning
- Value-Based Reinforcement Learning-DQN
- 强化学习的学习之路(二十三)_2021-01-23:Distributional DQN:A Distributional Perspective on Reinforcement Learning
热门文章
推荐文章
相关标签
推荐问答
- Selecting non-highlighted rows in excel
- How can I append data from a old dataframe onto a new, blank dataframe
- How to turn every 0 into a -1 in a array list in the fastest way?
- Accessing JSON Body with C#
- Spring Security: isAuthenticated using Ajax
- Multiple MS SQL databases as one datasource
- Is it possible to remove from an indexed data structure and avoid shifting at the same time?
- Cognos LIKE function problems
- Regression plot is wrong (python)
- Unable to bind a ResourceDictionary item to Rectangle.Child