为什么我的DQN在Breakout V0上的代理商不学习?
我使用了Chainerrl,并尝试了Breakout V0。
我运行此代码。它确实有效,但我的经纪人无法获得奖励(奖励始终低于5分)。
Python 2.7 Ubuntu 14.04
请教我为什么我不能。
我也不明白为什么异端号为972> l5 = l.linear(972,512)
import chainer
import chainer.functions as F
import chainer.links as L
import chainerrl
import gym
import numpy as np
from chainer import cuda
import datetime
from skimage.color import rgb2gray
from skimage.transform import resize
env = gym.make('Breakout-v0')
obs = env.reset()
print("observation space : {}".format(env.observation_space))
print("action space : {}".format(env.action_space))
action = env.action_space.sample()
obs, r, done, info = env.step(action)
class QFunction(chainer.Chain):
def __init__(self,obs_size, n_action):
super(QFunction, self).__init__(
l1=L.Convolution2D(obs_size, 4, ksize=2,pad=1),#210x160
bn1=L.BatchNormalization(4),
l2=L.Convolution2D(4, 4, ksize=2,pad=1),#105x80
bn2=L.BatchNormalization(4),
#l3=L.Convolution2D(64, 64, ksize=2, pad=1),#100x100
#bn3=L.BatchNormalization(64),
#l4=L.Convolution2D(64, 3, ksize=2,pad=1),#50x50
# bn4=L.BatchNormalization(3),
l5=L.Linear(972, 512),
out=L.Linear(512, n_action, initialW=np.zeros((n_action, 512), dtype=np.float32))
)
def __call__(self, x, test=False):
h1=F.relu(self.bn1(self.l1(x)))
h2=F.max_pooling_2d(F.relu(self.bn2(self.l2(h1))),2)
#h3=F.relu(self.bn3(self.l3(h2)))
#h4=F.max_pooling_2d(F.relu(self.bn4(self.l4(h3))),2)
#print h4.shape
return chainerrl.action_value.DiscreteActionValue(self.out(self.l5(h2)))
n_action = env.action_space.n
obs_size = env.observation_space.shape[0] #(210,160,3)
q_func = QFunction(obs_size, n_action)
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
gamma = 0.99
explorer = chainerrl.explorers.ConstantEpsilonGreedy(
epsilon=0.2, random_action_func=env.action_space.sample)
replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6)
phi = lambda x: x.astype(np.float32, copy=False)
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
minibatch_size=4, replay_start_size=100, update_interval=10,
target_update_interval=10, phi=phi)
last_time = datetime.datetime.now()
n_episodes = 10000
for i in range(1, n_episodes + 1):
obs = env.reset()
reward = 0
done = False
R = 0
while not done:
env.render()
action = agent.act_and_train(obs, reward)
obs, reward, done, _ = env.step(action)
if reward != 0:
R += reward
elapsed_time = datetime.datetime.now() - last_time
print('episode:', i,
'reward:', R,
)
last_time = datetime.datetime.now()
if i % 100 == 0:
filename = 'agent_Breakout' + str(i)
agent.save(filename)
agent.stop_episode_and_train(obs, reward, done)
print('Finished.')
看答案
作为Chainerrl的作者,如果您想解决Atari环境,我建议您从 examples/ale/train_*.py 并逐步自定义。深度强化学习对超参数和网络体系结构的变化确实很敏感,如果您一次引入很多变化,很难说出哪种变化是导致培训失败的原因。
我尝试在通过打印统计信息的同时运行您的脚本 agent.get_statistics() 发现Q值越来越高,这表明训练进展不佳。
$ python yourscript.py
[2017-07-10 18:14:45,309] Making new env: Breakout-v0
observation space : Box(210, 160, 3)
action space : Discrete(6)
episode: 1 reward: 0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 2 reward: 1.0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 3 reward: 0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 4 reward: 0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 5 reward: 2.0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 6 reward: 0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 7 reward: 1.0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 8 reward: 2.0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 9 reward: 1.0
[('average_q', 0.0), ('average_loss', 0.0)]
episode: 10 reward: 2.0
[('average_q', 0.05082079044988309), ('average_loss', 0.0028927958279822935)]
episode: 11 reward: 4.0
[('average_q', 7.09331367665307), ('average_loss', 0.0706595716528489)]
episode: 12 reward: 0
[('average_q', 17.418094266218915), ('average_loss', 0.251431955409951)]
episode: 13 reward: 1.0
[('average_q', 40.903169833428954), ('average_loss', 1.0959175910071859)]
episode: 14 reward: 2.0
[('average_q', 115.25579476118122), ('average_loss', 2.513677824600575)]
episode: 15 reward: 2.0
[('average_q', 258.7392539556941), ('average_loss', 6.20968827451279)]
episode: 16 reward: 1.0
[('average_q', 569.6735852049942), ('average_loss', 19.295426012437833)]
episode: 17 reward: 4.0
[('average_q', 1403.8461185742353), ('average_loss', 32.6092646561004)]
episode: 18 reward: 1.0
[('average_q', 2138.438909199657), ('average_loss', 44.90832410172697)]
episode: 19 reward: 1.0
[('average_q', 3112.752923036582), ('average_loss', 88.50687458947431)]
episode: 20 reward: 1.0
[('average_q', 4138.601621651058), ('average_loss', 106.09160137599618)]
智能推荐
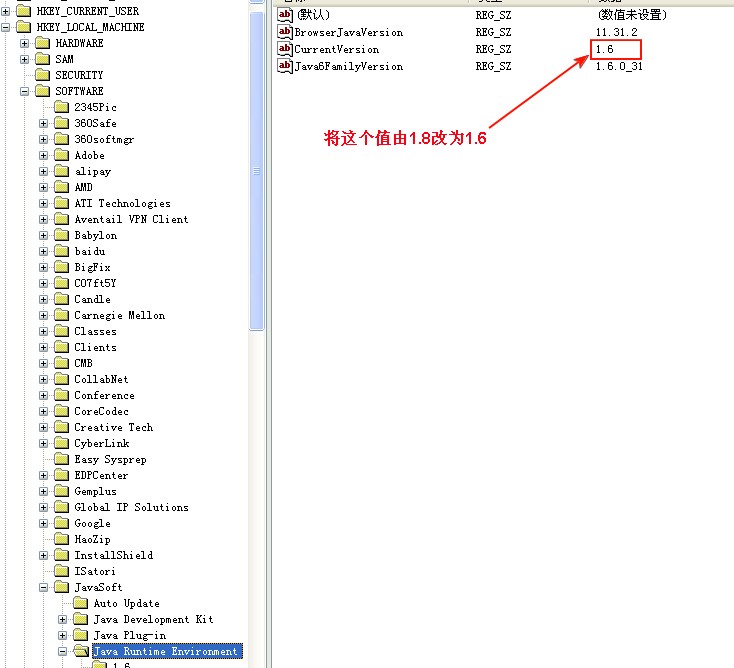
winXP JDK由1.8改为1.6
(1)直接在环境变量中删除配置的相关路径 path的值: 删除配置的Oracle变量,如下所示: (2)执行java -version命令后报错 按提示更改注册表的相关键值: 重新打开一个cmd,执行java -version,命令正常执行: ...

php中 isset()和empty()的区别
直接上代码(注意最后结尾总结) 响应 引用手册解释 empty用于做是否有值的判断 isset用于做变量是否存在判断 需要注意的是 isset 测试的变量值为null的时候会返回false 值为 空、0、false、空数组的时候返回的是true...
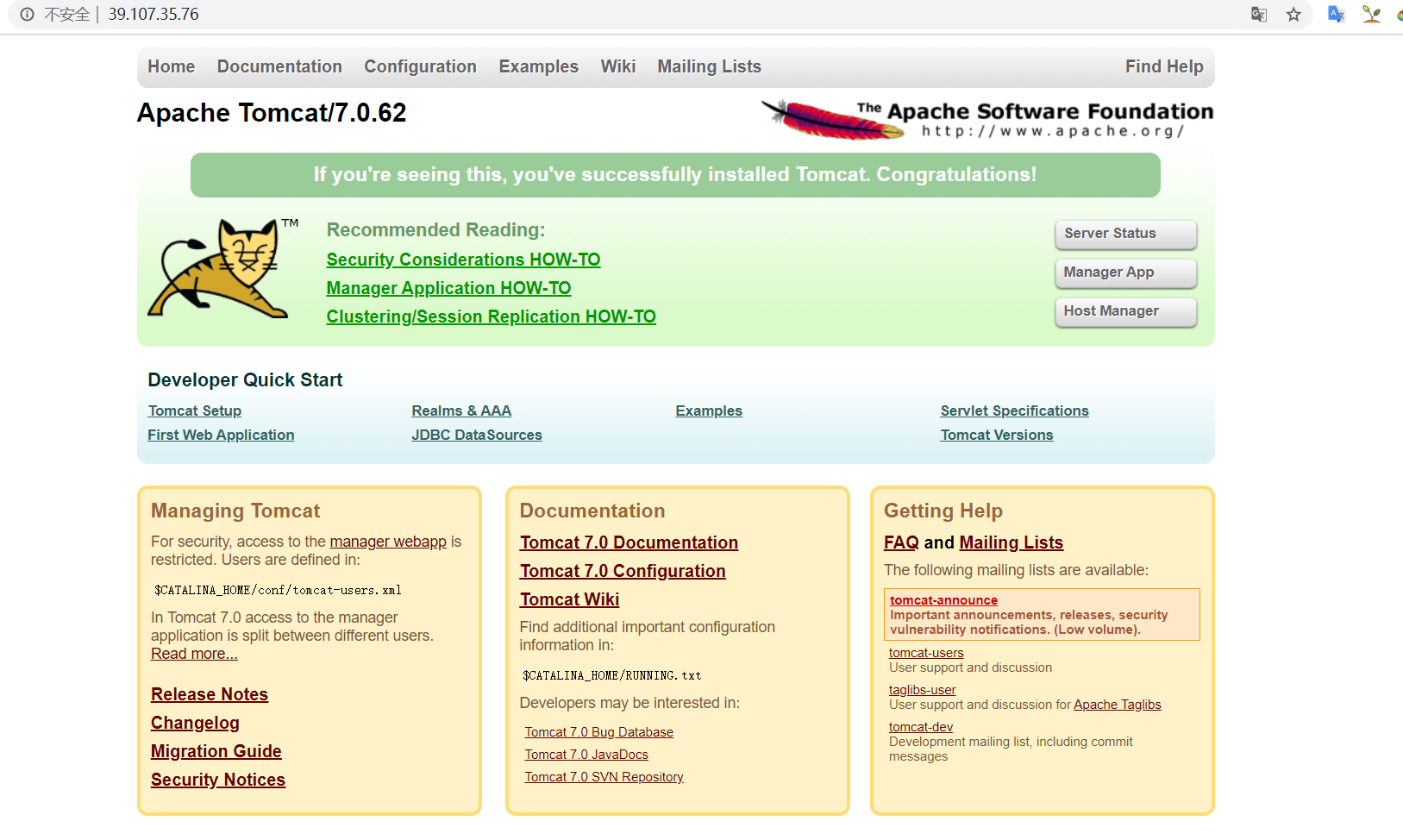
Docker-Tomcat为何看不到访问界面?
问题:源服务器未能找到目标资源的表示或者是不愿公开一个已经存在的资源表示? 开门见山: 说白了就是最新的Tomcat8.5版本的webapps下无欢迎页 Docker内的webapps目录 Tomcat7.0下的目录 怎么才看看到小猫呢 1.Docker内下载7.0版本的Tomcat 2.自己制作新的镜像(初学者可以尝试一下)...
初识Restful架构
初识Restful架构 起源 REST这个词,是Roy Thomas Fielding在他2000年的博士论文《Architectural Styles and the Design of Network-based Software Architectures》中提出的。 《CHAPTER 5 Representational State Transfer (REST)》是REST的章节。 名称...
Java中Int和Char类型之间的那些事
Java中Int和Char类型之间的那些事——转换、相加... 前景: 在LeetCode上刷到的一到深度优先的题#529#(https://leetcode-cn.com/problems/minesweeper/),题目如下: 题目的解答不是本次的重点,想了解答题思路的可以到链接中的官方解答或评论中了解。 在评论中看到有网友对题目的官方解答中,题述的第三点规则作出的处理...
猜你喜欢
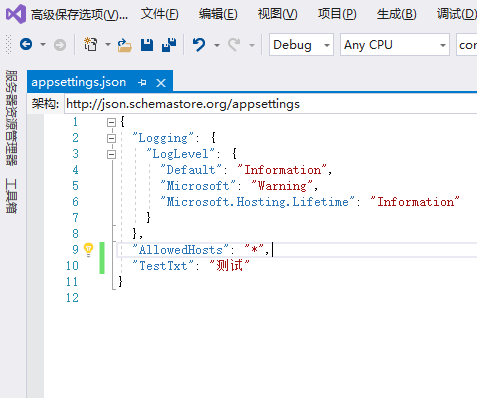
Net Core 读取appsettings.json 文件中文乱码的问题(使用高级选项保存解决)
一、打开appsettings.json 二、菜单栏中的“工具”-“自定义” 打开 三、切换到“命令”栏,点击“添加命令” 四、在弹出的命令框中在左侧选择 “文件” ,在文件中从右侧找到-高级保存选项,点击确定 五、点击“高级保存选项”...
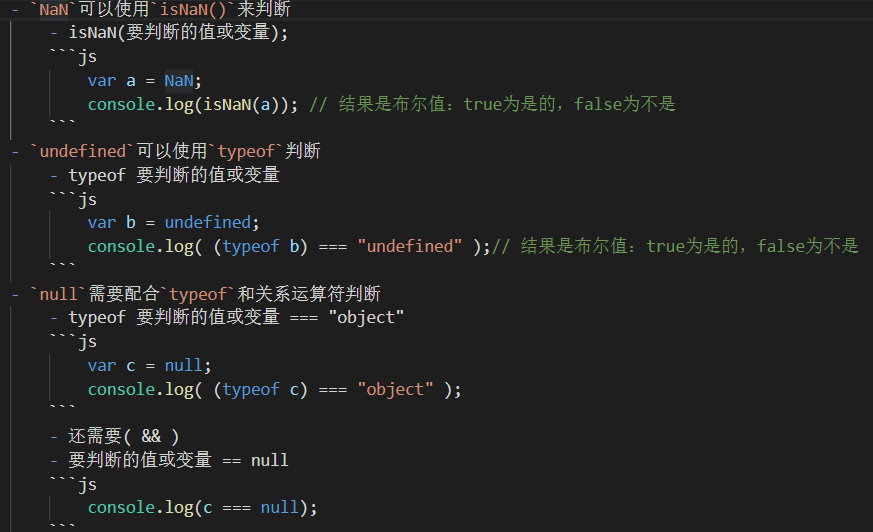
JS中三大特殊数据和如何判断
js中的三大特殊数据 undefined,null,NaN: NaN`:非法的数值运算得到的结果 特殊之处: 是一个数值型的数据,但是不是一个数字 NaN不等于任何值,和任何数据都不相等,NaN不等于NaN 检测方法:isNaN(要检测的数据) true:检测结果为 NaN 或能转成 NaN false:检测结果不是 NaN 或不能转成 NaN undefined是:未赋值,类型是undefine...
合并多个Word文档
想将多个文档中的内容合并到一个文档里,你还在用复制粘贴吗?如果有,那赶紧看看附图中的方法吧。 1.在“插入”选项卡中点击“对象”中的“文件中的文件” 2.选中几个文档 3.点击“插入” 群福利 群号码:615147109 1. Office安装程序及**。 2. PPT模版,简历模版。 3. 原创图文教...

谷歌发布TensorFlow 1.4与TensorFlow Lattice:利用先验知识提升模型准确度 搜狐科技 10-12 15:29 选自:Google Research Blog 参与:李泽南、
谷歌发布TensorFlow 1.4与TensorFlow Lattice:利用先验知识提升模型准确度 昨天,谷歌发布了 TensorFlow 1.4.0 先行版,将 tf.data 等功能加入了 API。同时发布的还有 TensorFlow Lattice,这家公司希望通过新的工具让开发者们的模型更加准确。 TensorFlow 1.4.0 先行版更新说明:https://github.com/...
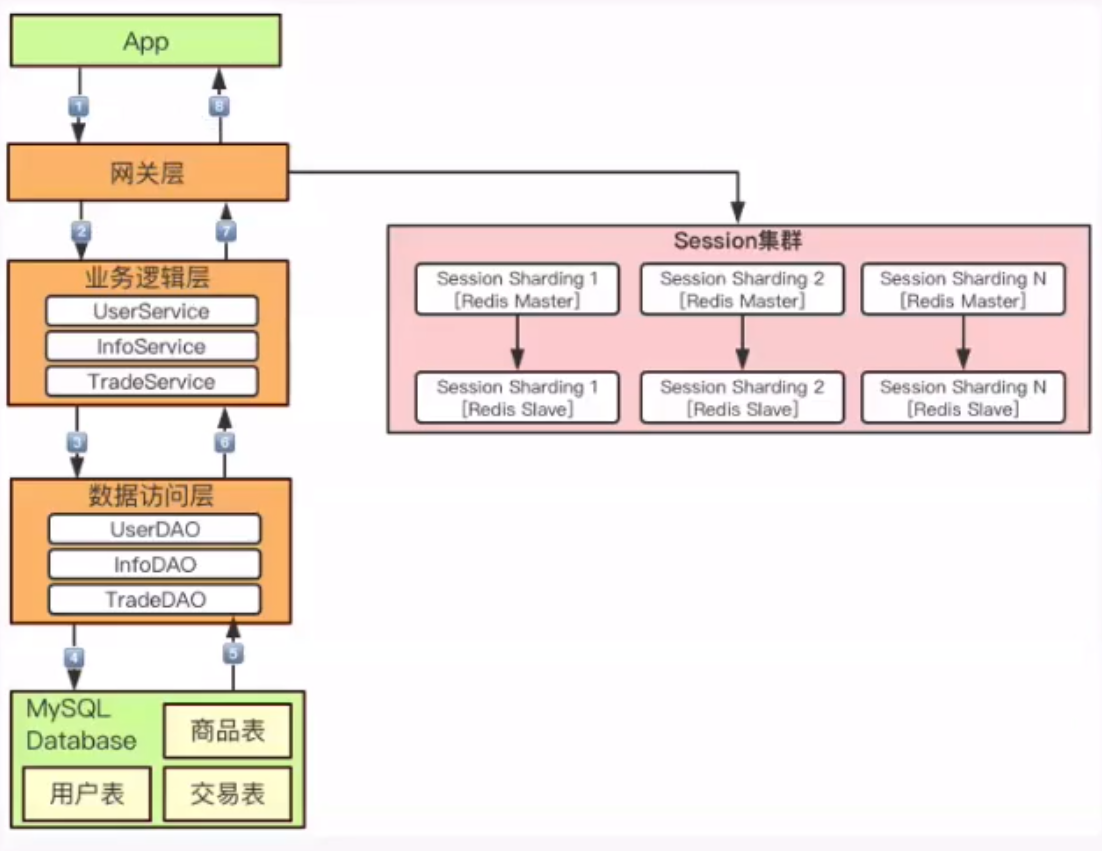
核心技术实践篇
核心技术实践篇 服务无状态化设计与实践 定义:(stateless) 同一服务冗余部署N份,N份完全对等 请求提交到任何一份冗余服务上,处理结果完全一致 目的:弹性扩缩容(同样属于高可用范畴) 快速扩容 弹性缩容 案例:用户session数据 通常session数据存储在session服务器,比如redis集群 redis集群存在的问题? 数据增长过快,集群扩容。 重新hash分布。 可以通过以下...
问答精选
How we can create Dataproc cluster through rest API or http request?
I am new in python, Here I want to create dataproc cluster using http request. I am following below dataproc documentation where they mentioned in REST API section. see below https://cloud.google.com/...
AddWithValue method on ASP.NET
I am using AddStringWithValue method in ASP.NET using C# My HTML code is My C# code for the method is: The problem is, it is giving red underline under email and password. Shouldn't we identify them w...
How to apply css using a condition?
I'm trying to apply this css: this works well, the problem is that the web app can set a class on the body called white-content, if the white-content class is setted, then I can't see the text of h2, ...
Tile game collision detection with sprite moving to arbitary (x,y)
So I am struggling with some logic for collision detection in my game. I have a grid of tiles(images), all representative of a value in a 2D array, so the location of tile N would be (column m, row n)...
Kotin sort by descending then ascending
Im trying to order a list on multiple parameters.. for example, one value descending, second value ascending, third value descending. is there a way like this to do it? (i know is incorrect) people = ...
相关问题
相关文章
热门文章
推荐文章
相关标签
推荐问答
- Selecting non-highlighted rows in excel
- How can I append data from a old dataframe onto a new, blank dataframe
- How to turn every 0 into a -1 in a array list in the fastest way?
- Accessing JSON Body with C#
- Spring Security: isAuthenticated using Ajax
- Multiple MS SQL databases as one datasource
- Is it possible to remove from an indexed data structure and avoid shifting at the same time?
- Cognos LIKE function problems
- Regression plot is wrong (python)
- Unable to bind a ResourceDictionary item to Rectangle.Child