强化学习(reforcement learning)之Deep Q-network(DQN)算法简介
技术标签: 机器学习基础 神经网络 机器学习 深度学习 人工智能

《强化学习》近似值函数方法
强化学习和监督学习 表格方法的局限 RL中的函数近似 监督学习-MC MC—TD 基于值函数的RL损失函数 近似方法的一些困难 Deep Q-Network 经验回放 目标网络 奖励裁剪 DQN的一些问题和解决 Q值自相关问题 Q值过度估计 优先经验回放 Bootstrap DQN 部分可见性

强化学习之Deep Q Network (DQN)
方法通过存储-采样的方法将这个关联性打破了。 ②fixed target q-network:Q值需要Q估计和Q现实两个估计值,那么这个策略就是在只有一个Q估计网络的情况下,复制一个结构完全一样的Q...导致Q表所占的空间很大,而且搜索速度会变慢,因此将Q-learning与强化学习相结合,用神经网络拟合Q值,会解决Q值矩阵过大的问题。 当环境中的状态数超过现代计算机容量时(Atari游戏有
论文阅读15:Massively Parallel Methods for Deep Reinforcement Learning
Q-network是在每一步由上面公式2来直接利用梯度进行更新网络。 Gorila DQN,是Q-network产生Q估计值,由target Q-network生成max Q,我们称其为Q目标值,target网络是在参数服务器进行了N不更新之后,复制参数到targetQ-network中,而Q-network是在每步之前复制参数服务器的当前参数进行更新网络。 3、稳定性 虽然DQN训练算法旨在通过强化学习
2020-11-03
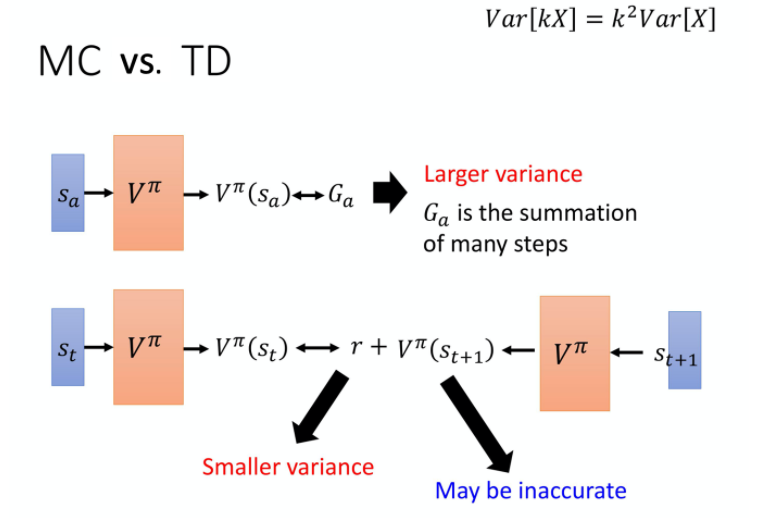
强化学习打卡之DQN DQN为了解决动作空间过大造成维数灾难问题在Q-learning的基础上引入了神经网络。DQN 主要是把 Q 函数通过价值函数近似方法转换为一个深度神经网络。神经网络输入的是... π(s)进行 Policy Evaluation(策略评估)。 MC VS.TD 由上图MC和TD的更新公式可知两者各有优劣,MC是一个episode得到的累计奖励值,所以偏差较大,但是方差

Reinforcement Learning(二):Value-Based
回顾一下action-value函数: Value-Based是指: 但是一般来说,这个Q*我们是无从得出的,因此提出使用卷积网络来近似: Deep Q-Network (DQN) Approximate the Q Function Deep Q Network (DQN) Apply DQN to Play Game Temporal Difference (TD) Learning 一个小
智能推荐
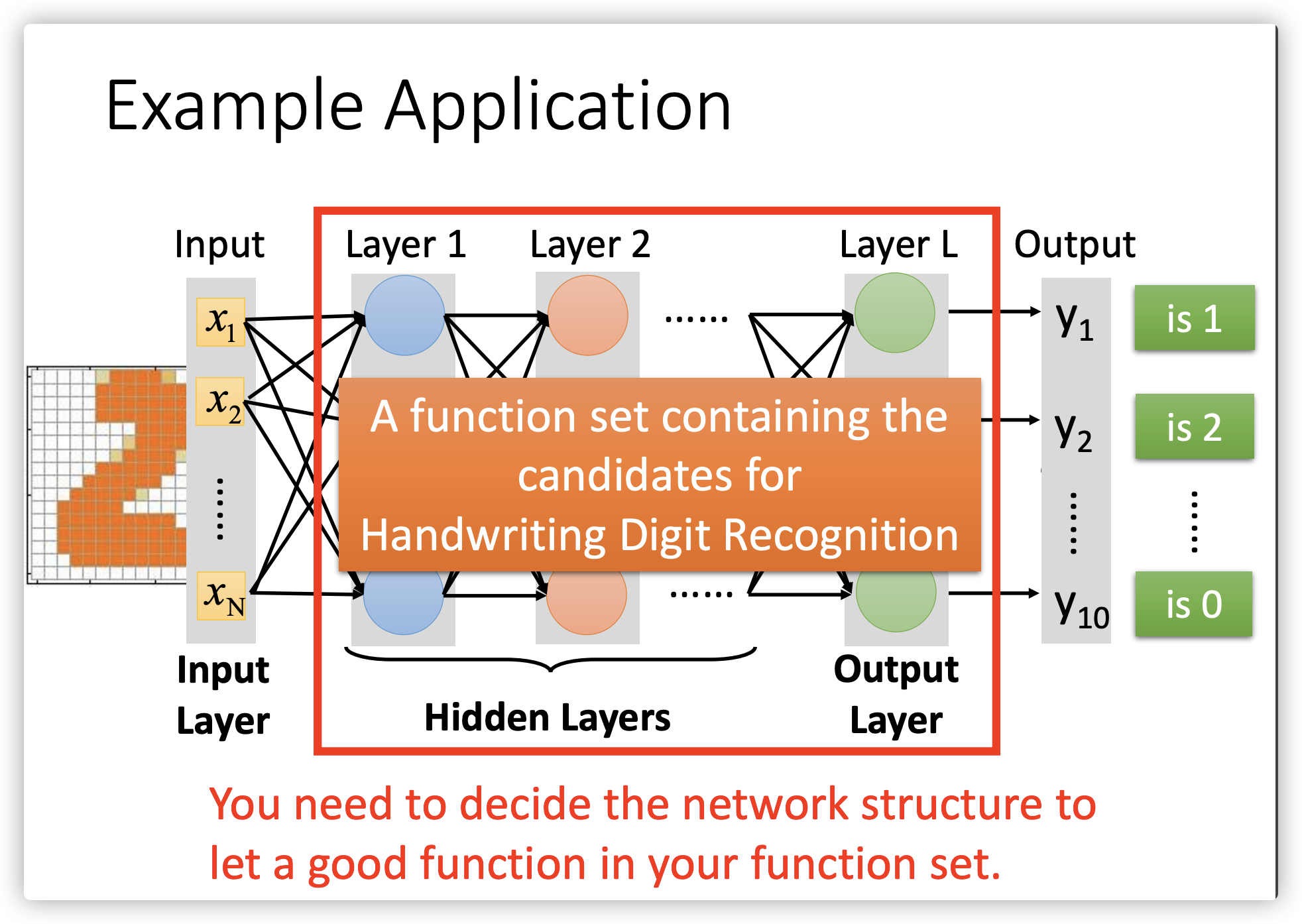
李宏毅机器学习之Deep Learning简介
一、深度学习的发展趋势 1958:Perceptron(linear model) 1969:Perceptron has limitation 1980:Multi-layer perceptron Do not have significant difference from DNN today 1986:Backpropagation Usually more than 3 hidden l...

深度强化学习deep reinforcement learning
Lecture content of deep reinforcement learning: An overview of reinforcement learning Markov decision process Monte Carlo method Model based reinforcement learning Reinforcement learning based on samp...

强化学习基础学习系列之强化学习简介
在看david silver的强化学习课程,顺便做做笔记,作为回顾复习,有些内容加上了自己的理解,不正确的话还望指出。 下面用到的图片均来自课程中的ppt,就不一一说明了,课程链接:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Home.html,优酷上有中文翻译的:http://v.youku.com/v_show/id_XMjcwNDA5NzIwOA=...
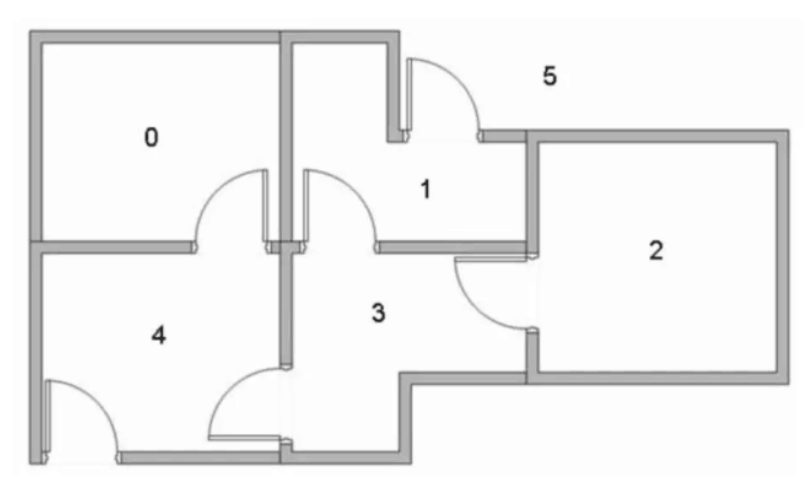
机器学习——强化学习Q_learning算法
假设有这样的房间 如果将房间表示成点,然后用房间之间的连通关系表示成线,如下图所示: 这就是房间对应的图。我们首先将agent(机器人)处于任何一个位置,让他自己走动,直到走到5房间,表示成功。为了能够走出去,我们将每个节点之间设置一定的权重,能够直接到达5的边设置为100,其他不能的设置为0,这样网络的图为: Qlearning中,最重要的就是“状态”和“动作...
强化学习(3):Deep Q Network(DQN)算法
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。 本文主要讲解有关 Deep Q Network(DQN)算法的相关内容。 1. DQN 的基本思想 传统的 Q-Learning 算法当 Q 表过大时不仅难以存储而且难以搜索,并且当状态是连续的话,用 Q 表存储是不现实的,这时可以用一个函数来拟合 Q 表,所以提出了神经网络和 Q-L...
猜你喜欢
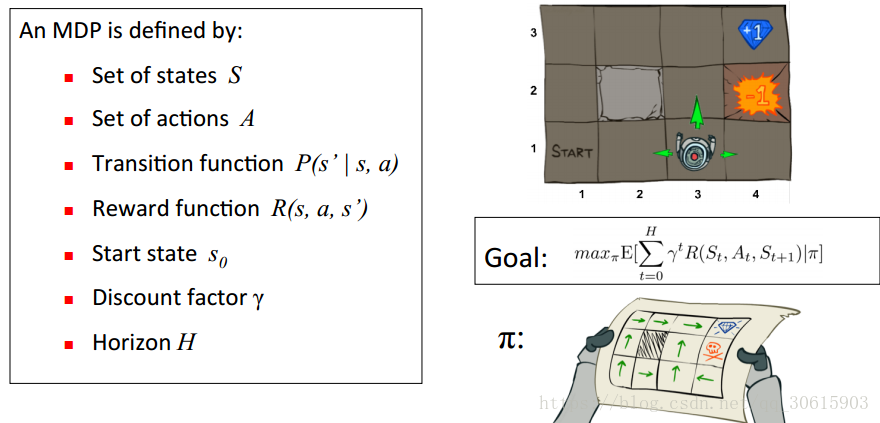
【强化学习】Q-Learning算法详解
【强化学习】Q-Learning详解 1、算法思想 QLearning是强化学习算法中值迭代的算法,Q即为Q(s,a)就是在某一时刻的 s 状态下(s∈S),采取 a (a∈A)动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward r,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取动作获得较大的收益...
强化学习:强化学习简介
强化学习:强化学习简介 一、简介 由于工作和研究的需要,不得不接触一部分的强化学习课程。而强化学习系列大部分原理都涉及到相当多的数学原理,啃起来也比较麻烦。我在学习的过程中,也是参考了多方资料,整个系列看下来,深感只有真正动手coding才能理解到强化学习的精髓吧。但碍于时间的限制,我并没有真正的去动手编程,而是粗略的去阅读了别人的源码,这一部分欠缺,等日后有时间了再补...

揭秘深度强化学习-5 评估奖励之Q-learning算法
看完觉得深受启发的一篇文章,根据自己的理解翻译过来留以后再次翻看 原文地址http://neuro.cs.ut.ee/demystifying-deep-reinforcement-learning/ Q-learning算法 在Q-learning算法中,我们定义一个函数Q(s,a) 来表示当我们在状态s采取行动a且之后都是最理想状态,我们预期未来能获得的衰减未来奖励 Q(s,a)可以视为s状态...
自定义类加载器
自定义类加载器 我们如果需要自定义类加载器,只需要继承ClassLoader类,并覆盖掉findClass方法即可。 自定义文件类加载器 自定义网络类加载器 热部署类加载器 当我们调用loadClass方法加载类时,会采用双亲委派模式,即如果类已经被加载,就从缓存中获取,不会重新加载。如果同一个class被同一个类加载器多次加载,则会报错。因此,我们要实现热...
用户界面和兼容性测试
用户界面测试 1 、导航测试 导航直观 Web系统的主要部分可通过主页存取 Web系统不需要站点地图、搜索引擎或其他的导航帮助 Web应用系统的页面结构、导航、菜单、连接的风格一致 2 、图形测试 图形有明确的用途 所有页面字体的风格一致。 背景颜色与字体颜色和前景颜色相搭配。 图片的大小减小到 30k 以下 文字回绕正确 3 、内容测试 Web应用系统提供的信息是正确的 信息无语法或拼写错误 可...
问答精选
How we can create Dataproc cluster through rest API or http request?
I am new in python, Here I want to create dataproc cluster using http request. I am following below dataproc documentation where they mentioned in REST API section. see below https://cloud.google.com/...
AddWithValue method on ASP.NET
I am using AddStringWithValue method in ASP.NET using C# My HTML code is My C# code for the method is: The problem is, it is giving red underline under email and password. Shouldn't we identify them w...
How to apply css using a condition?
I'm trying to apply this css: this works well, the problem is that the web app can set a class on the body called white-content, if the white-content class is setted, then I can't see the text of h2, ...
Tile game collision detection with sprite moving to arbitary (x,y)
So I am struggling with some logic for collision detection in my game. I have a grid of tiles(images), all representative of a value in a 2D array, so the location of tile N would be (column m, row n)...
Kotin sort by descending then ascending
Im trying to order a list on multiple parameters.. for example, one value descending, second value ascending, third value descending. is there a way like this to do it? (i know is incorrect) people = ...
相关问题
相关文章
热门文章
推荐文章
相关标签
推荐问答
- Selecting non-highlighted rows in excel
- How can I append data from a old dataframe onto a new, blank dataframe
- How to turn every 0 into a -1 in a array list in the fastest way?
- Accessing JSON Body with C#
- Spring Security: isAuthenticated using Ajax
- Multiple MS SQL databases as one datasource
- Is it possible to remove from an indexed data structure and avoid shifting at the same time?
- Cognos LIKE function problems
- Regression plot is wrong (python)
- Unable to bind a ResourceDictionary item to Rectangle.Child