Apache Spark Streaming的优点
Apache Spark Streaming的优点:
(1)优势及特点
1)多范式数据分析管道:能和 Spark 生态系统其他组件融合,实现交互查询和机器学习等多范式组合处理。
2)扩展性:可以运行在 100 个节点以上的集群,延迟可以控制在秒级。
3)容错性:使用 Spark 的 Lineage 及内存维护两份数据进行备份达到容错。 RDD通过 Lineage 记录下之前的操作,如果某节点在运行时出现故障,则可以通过冗余备份数据在其他节点重新计算得到。
对于 Spark Streaming 来说,其 RDD 的 Lineage 关系如图 3 所示,图中的每个长椭圆形表示一个 RDD,椭圆中的每个圆形代表一个 RDD 中的一个分区(Partition),图中的每一列的多个 RDD 表示一个 DStream(图中有 3 个 DStream), t=1 和 t=2 代表不同的分片下的不同 RDD DAG。图中的每一个 RDD 都是通 过 Lineage 相 连 接 形 成 了 DAG, 由 于 SparkStreaming 输入数据可以来自于磁盘,例如 HDFS(通常由三份副本)也可以来自于网络(Spark Streaming 会将网络输入数据的每一个数据流复制两份到其他的机器)都能通过冗余数据及 Lineage 的重算机制保证容错性。所以 RDD 中任意的 Partition 出错,都可以并行地在其他机器上将缺失的 Partition 重算出来。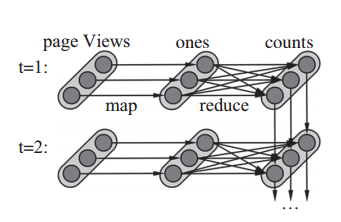
图 3 Spark Streaming 容错性
4)吞吐量大:将数据转换为 RDD,基于批处理的方式,提升数据处理吞吐量。图4 是 Berkeley 利用 WordCount 和 Grep 两个用例所做的测试。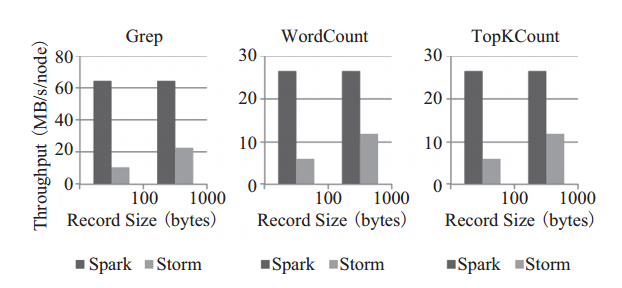
图4 Spark Streaming 与 Storm 吞吐量比较图
5)实时性: Spark Streaming 也是一个实时计算框架, Spark Streaming 能够满足除对实时性要求非常高(例如:高频实时交易)之外的所有流式准实时计算场景。目前Spark Streaming 最小的 Batch Size 的选取在 0.5 ~ 2s(对比: Storm 目前最小的延迟是100ms 左右)。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5725940.html,如需转载请自行联系原作者
来源:https://yq.aliyun.com/articles/371166
智能推荐
Apache Spark渐进式学习教程(二):核心模块 Spark Core, Spark SQL, Spark Streaming, MLib 介绍
目录 前言:spark 软件栈图 一,Spark Core 二,Spark SQL 三,Spark Streaming 四,MLib 前言:spark 软件栈图 一,Spark Core Spark Core 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dat...

Apache Spark的部署环境的小记
Spark的单机版便于测试,同时通过SSH用Spark的内置部署脚本搭建Spark集群,使用Mesos、Yarn或者Chef来部署Spark。对于Spark在云环境中的部署,比如在EC2(基本环境和ECMR)上的部署。 请移步,见我的下面博客 Spark运行模式概述 注意:EMR(Elastic MapReduce),即弹性MapRedu...
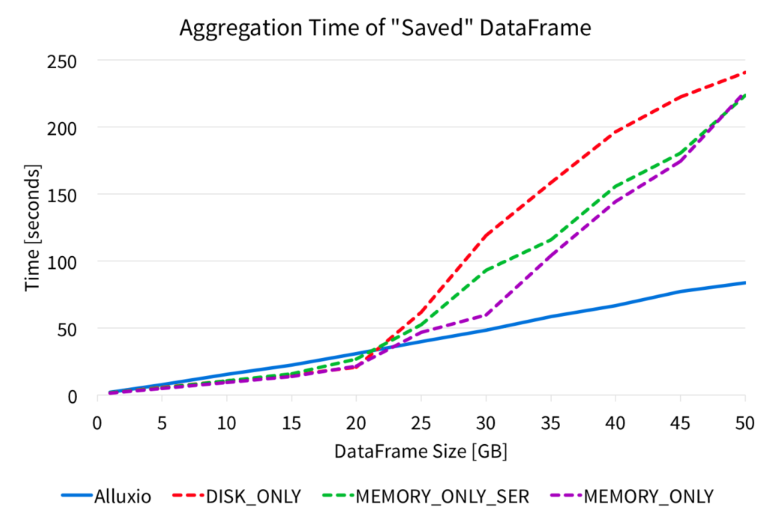
使用Alluxio的Apache Spark DataFrame缓存
目录: 1.介绍 2.Alluxio和Spark训练 3.保存数据框 Spark存储级别: MEMORY_ONLY:将Java对象存储在Spark JVM内存中 MEMORY_ONLY_SER:将序列化的Java对象存储在Spark JVM内存中 DISK_ONLY:将数据存储在本地磁盘上 4.在Alluxio中查询“保存的”数据帧 5. 与Alluxio共享“...
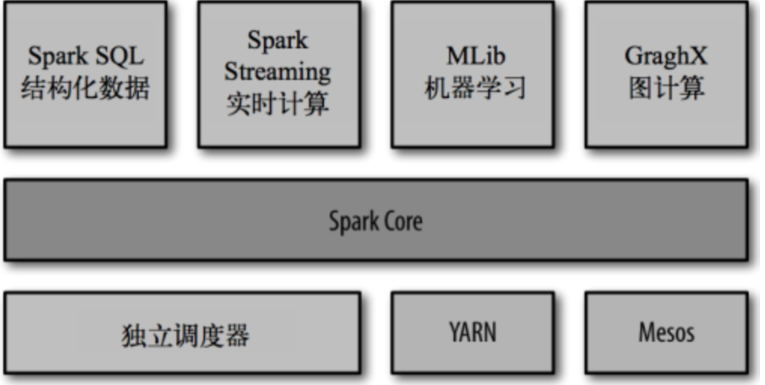
Apache Spark 完善的生态圈
Spark完善的生态圈 目前,Spark已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目 Spark Core:实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。 Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL操作...

使用Apache Spark设置Tableau的指南
https://community.tableau.com/docs/DOC-7638 Apache Spark是大数据分析中最热门的事情,而Tableau是最热门的数据可视化和发现工具之一。将它们组合在一起,您就可以在大数据分析和可视化领域获得潜在的游戏规则改变。 Tableau 9支持与Spark一起使用,但设置并非完全直截了当,直到您正确设置后端组件设置。 技术堆...
猜你喜欢
Apache Spark 在eBay 的优化
供稿 | eBay DSS Team 作者 | 田川晓阳 编辑 | 顾欣怡 本文4490字,预计阅读时间14分钟 导读 新一代数据开发分析平台Zeta由eBay DSS(Data Services and Solutions) 团队自主研发,主要针对在Spark SQL运行过程中可能存在的性能隐患及Spark执行计划图的缺陷,提出相应解决方案,旨在降低Spark SQ...

Apache Spark GraphX的体系结构
1. 整体架构 GraphX 的整体架构如图 1所示可以分为三部分。 图 1 GraphX 架构 存储和原语层 Graph 类是图计算的核心类。内部含有 VertexRDD、 EdgeRDD 和RDD[EdgeTriplet] 引用。 GraphImpl 是 Graph 类的子类实现了图操作。 接口层在底层 RDD 的基础之上...

Apache Spark的Lambda架构示例应用
文章讲的是Apache Spark的Lambda架构示例应用,目前,市场上很多玩家都已经成功构建了MapReduce工作流程,每天可以处理TB级的历史数据,但是在MapReduce上跑数据分析真的太慢了。所以我们给大家介绍利用批处理和流处理方法的Lambda架构,本文中将利用Apache Spark(Core,SQL,Streaming),Apache Parquet,Twitter Stream...
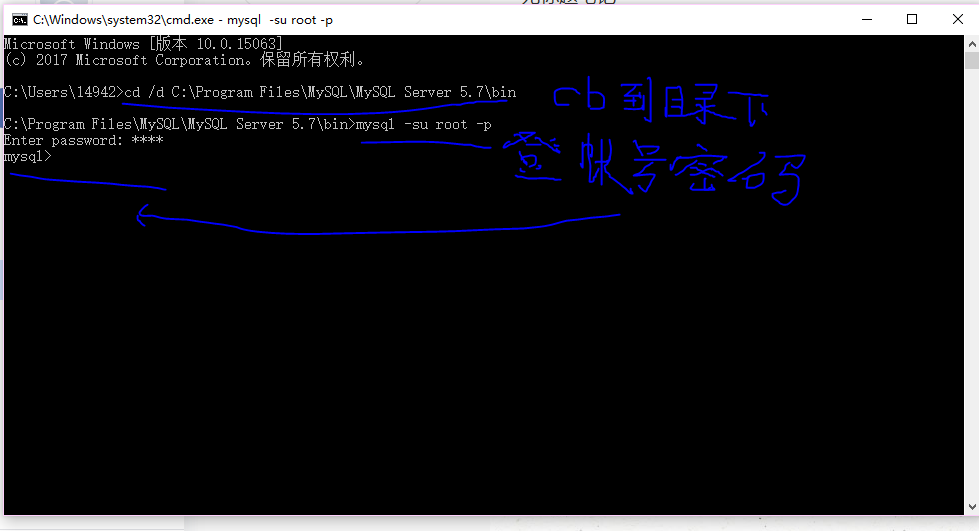
Mysql基本使用技巧
通过几天简单的学习,我掌握了一点基本的mysql操作步骤,下面是我的学习笔记,分享给大家,共同学习。我们都知道数据库在我们开发学习工作中必不可少,mysql作为一种被广泛使用的数据库,所以我们的学习必不可少。 使用mysql我们需要下载安装好所有的工具,在此我不在一一介绍,接下来,我们切入主题,MySQL的简单操作,下面是使用步骤。(我的所有步骤均是在windows下的命令行窗口完成的...
Apache Spark Streaming的优点
Apache Spark Streaming的优点: (1)优势及特点 1)多范式数据分析管道:能和 Spark 生态系统其他组件融合,实现交互查询和机器学习等多范式组合处理。 2)扩展性:可以运行在 100 个节点以上的集群,延迟可以控制在秒级。 3)容错性:使用 Spark 的 Lineage 及内存维护两份数据进行备份达到容错。 RDD通过 Lineage 记录下之前的操作,如果某节点在运...
问答精选
Python Regex Matching
I am inputting a text file (Line)(all strings). I am trying to make card_type to be true so it can enter the if statement, however, it never enters the IF statement. The output that comes out from the...
Can't insert this JSON data to SQL Server?
I'm trying to insert the following JSON data into a table on our SQL Server with python code. And if I could solve this with executing a SQL statement, I would be so happy. Because our Application ser...
Spring Instance Factory not working
I started learning spring recently and doing a simple demo of Instance factory but getting error. Java Bean: Interface: Factory: Spring config When I run the code by getting Bike Object from context, ...
How to track direct URL referrer
Most hosts come with softwares or google analytics which allows you to know how a person got to your site, for example: a link on yelp.com or a facebook.com page link. But it is impossible for the sof...
String range search over a RAW datatype
We are using an oracle table as a simple event store, in this table we are saving the message ids (.Net GUID using a SequentialGuidComb) as RAW(16). We are writing a consuming application which needs ...
相关问题
- Apache Spark的分区
- Spark,Kafka集成问题:对象Kafka不是org.apache.spark.streaming的成员
- 如何在Apache Spark的Apache Spark中注册UDF
- Apache Spark的性能调整
- 从Apache Spark Streaming Context访问JAR中的Resources目录中的文件
- 在Apache Spark Streaming中使用ForeachRDD中的DB连接
- value saveastextfile不是org.apache.spark.streaming.dstream.dstream [(String,Long)]的成员
- 对象Twitter不是Package org.apache.spark.streaming的成员
- 无法导入org.apache.spark.streaming.kafka010
- java.lang.noclassdeffounderror:org/apache/spark/streaming/kafka/kafkautils
相关文章
- Apache 流框架 Flink,Spark Streaming,Storm
- Apache Spark和Apache Flink的区别
- Apache Spark和Apache Storm的区别
- Apache Spark 流行的原因
- Apache Spark
- Apache Spark
- 日志系统---从 Spark Streaming 到 Apache Flink:bilibili 实时平台的架构与实践
- 从 Spark Streaming 到 Apache Flink : 实时数据流在爱奇艺的演进
- Apache 流框架 Flink,Spark Streaming,Storm对比分析
- Apache 流框架 Flink,Spark Streaming,Storm对比分析
热门文章
推荐文章
相关标签
推荐问答
- How do I calculate the difference of two alias for sorting
- Error using discord bot on my ubuntu server
- How to fix this JsonMappingException: N/A during XML deserialization
- RxJava's switchOnNext method does not behave as JavaDoc described
- Nested/inner classes in WCF?
- Return array from INDEX function in Excel?
- Powershell Invoke-RestMethod Paging
- Is select/poll keep checking for data during wait or just check once when data available?
- apache nifi: hive closes connection and workflows stop working
- Laravel 8 UniSharp File Manager 3 change base directory from app/storage to app/public