Kylin增量构建
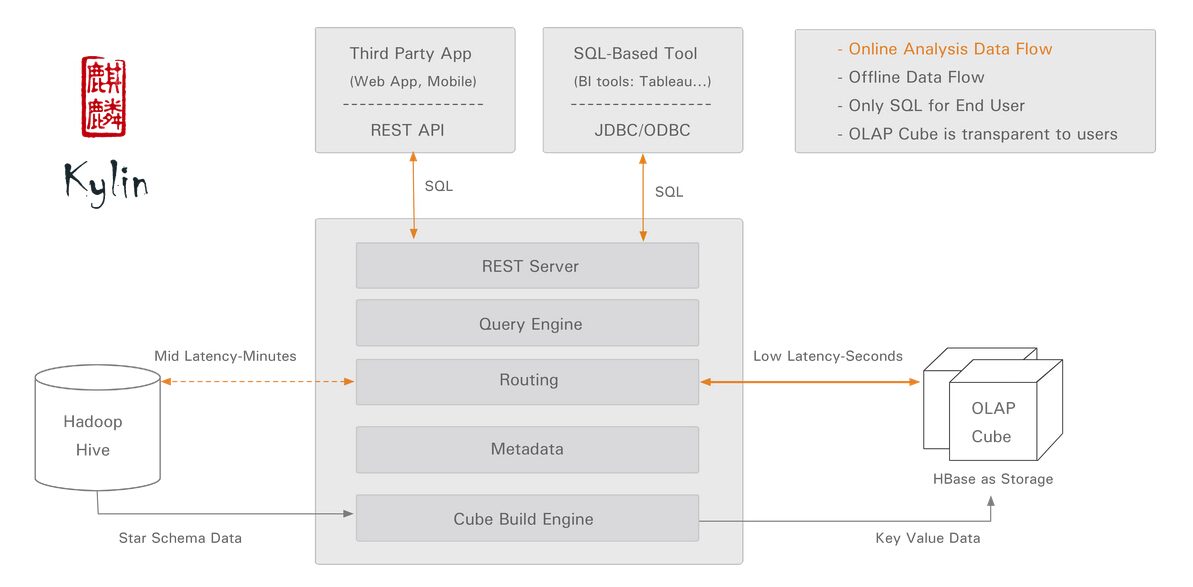
分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例
查询能力,多维立方体(MOLAP Cube) 用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体。 与BI工具及其他应用整合 提供JDBC及ODBC驱动,与BI工具整合。 其他特性 压缩与...); Kylin中建立数据源; Kylin中建立数据模型; Kylin中建立Cube; Build Cube; 查询Cube; Kylin按照上面的过程,最终将Hive中的事实表按照相应的结构,压缩并存储在
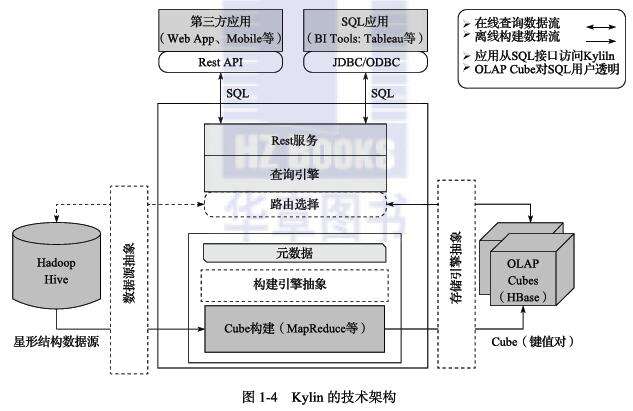
可扩展超快OLAP引擎: Kylin
也就是RowKey是由各个维度的值拼接而成的。 4、构建Cube:增量构建和全量构建 5、历史数据刷新、合并(Segment) 6、查询Cube,标准的SQL的select语句。 支持构建方式: 增量...仓库中的数据会随着时间的增长而增长,而Cube Segment也是按时间顺序来构建的。 Apache Kylin的主要使用过程: 1、数据准备:符合星型模型、维度表设计(Kylin将维度表加载到内存中处理

原来Kylin的增量构建,大有学问!
应用场景 Kylin在每次Cube的构建都会从Hive中批量读取数据,而对于大多数业务场景来说,Hive中的数据处于不断增长的状态。为了支持Cube中的数据能够不断地得到更新,且无需重复地为已经处理过...关于Kylin的增量构建的步骤过程,以及其与全量构建的差异对比!看完之后,相信你也一定能够感受到这里面的大学问~ 文章目录 Kylin增量构建 应用场景 理解Cube、Cuboid与Segment的关系
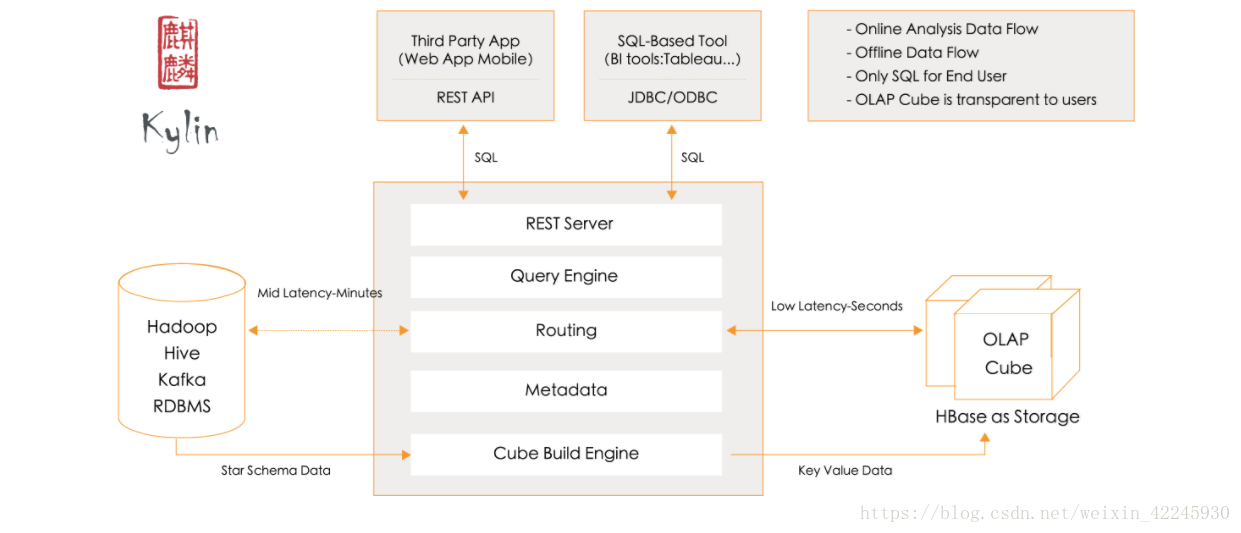
Apache Kylin 的介绍
ANSI SQL 接口: Kylin为Hadoop提供标准SQL支持大部分查询功能 交互式查询能力: 通过Kylin,用户可以与Hadoop数据进行亚秒级交互,在同样的数据集上提供比Hive更好的性能 多维立方体(MOLAP Cube): 用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体 与BI工具无缝整合:Kylin提供与BI工具的整合能力,如Tableau,PowerBI
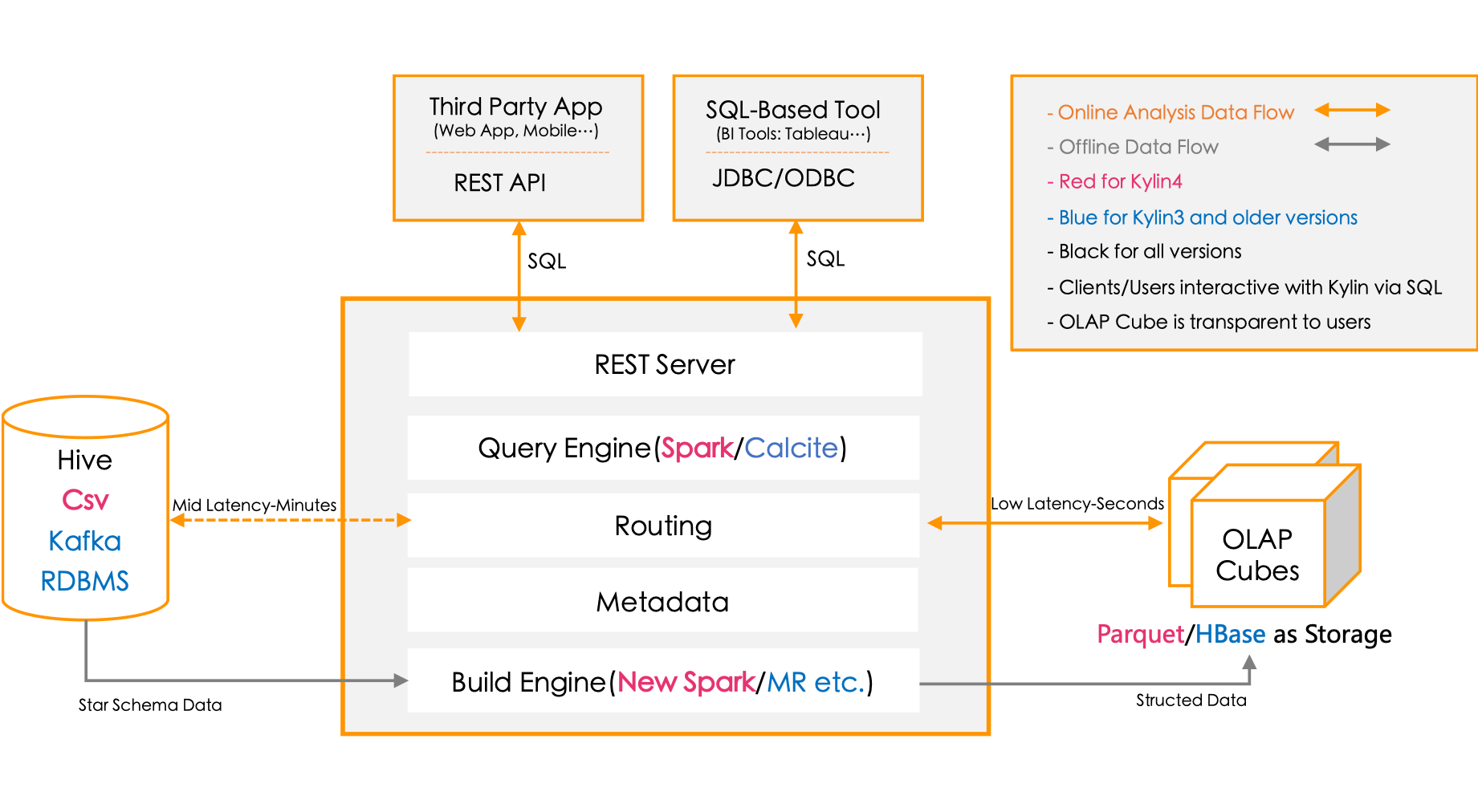
Kylin介绍
进行亚秒级交互,在同样的数据集上提供比Hive更好的性能 - 多维立方体(MOLAP Cube): 用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体 - 与BI工具无缝整合: Kylin...(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。 Kylin是什么? - 可扩展超快OLAP引擎: Kylin是为减少在
智能推荐
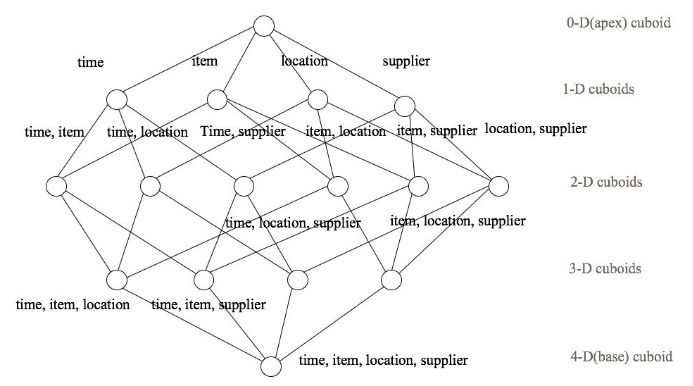
Kylin Cube构建原理
Kylin Cube构建原理 目录 Kylin Cube构建原理 1. 维度和度量 2. Cube和Cuboid 3. Cube存储原理 4. Cube构建算法 1)逐层构建算法(layer) 2)快速构建算法(inmem) 1. 维度和度量 维度:即观察数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时间或者地区的维度来观察。维度是一组离散的值,比如说性别中的男和女,或者时...
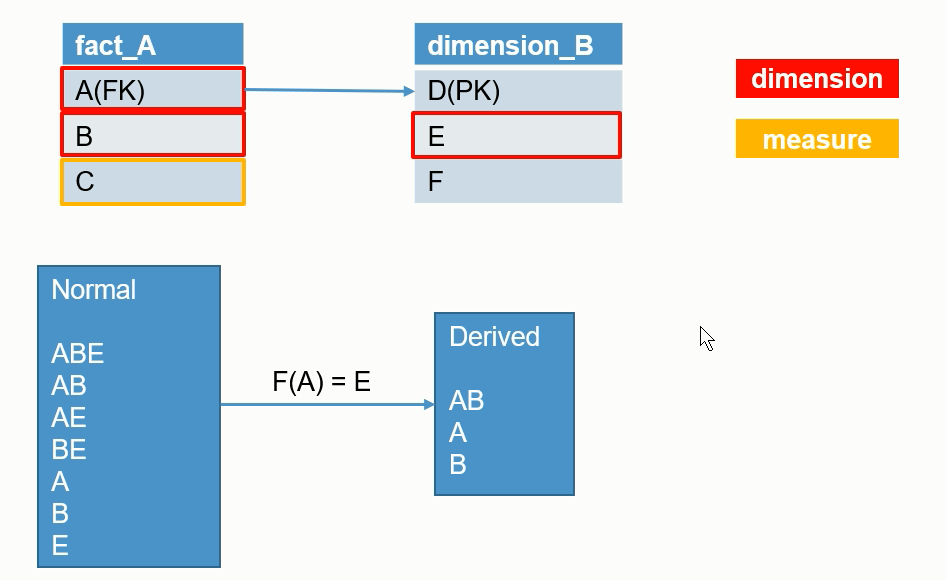
Kylin之Cube构建优化
在没有采取任何优化措施的情况下,Kylin会对每一种维度的组合进行预计算,每种维度的组合的预计算结果被称为Cuboid。假设有4个维度,我们最终会有24 =16个Cuboid需要计算。 但在现实情况中,用户的维度数量一般远远大于4个。假设用户有10 个维度,那么没有经过任何优化的Cube就会存在210 =1024个Cuboid;而如果用户有20个维度,那么Cube中总共会存在220 =104857...
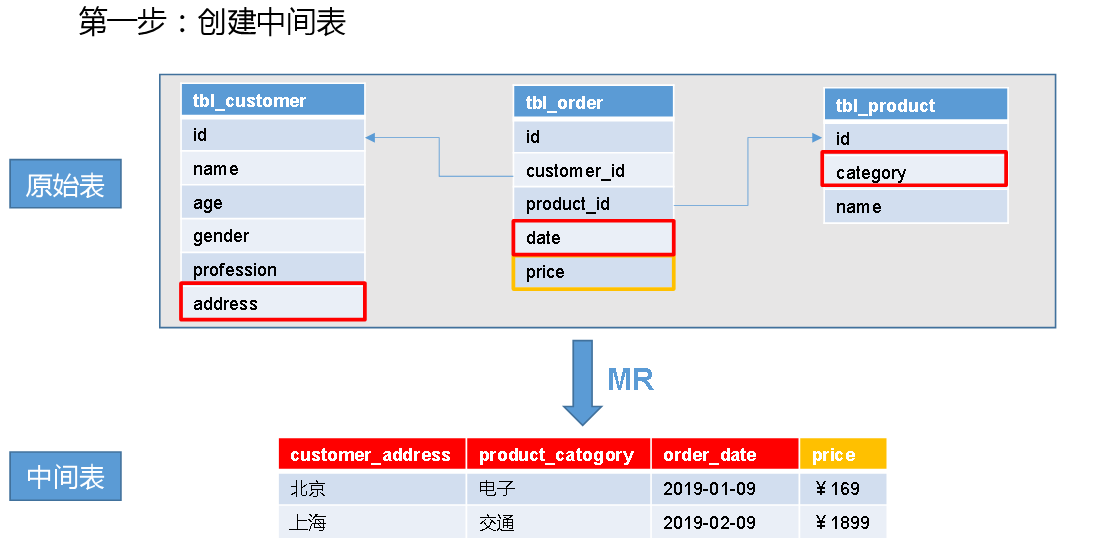
Kylin之Cube构建原理
目录 一、Cube构建流程 1.1、创建中间表 1.2、将中间表的数据均匀分配到不同的文件 1.3、创建维度字典表 1.4、多维度构建cube(重要) 1.5、Hbase K-V映射 1.6、将cube data转成HFile格式并导入HBase 二、Cube构建算法 2.1、逐层构建算法(layer) 2.2、快速构建算法(inmem) 一、Cube构建流程 1.1、创建中间表 1.2、将中间表...
使用 DolphinScheduler 调度 Kylin 构建
原创 史少锋@Kyligence apachekylin 前天 01 背景 Apache Kylin 是一个支持海量大数据的在线分析引擎,需要离线或流式地从Apache Hive, Apache Kafka加载数据。通常当上游数据准备好以后,用户需要使用Kylin的Web界面或API触发以生成数据加载的任务。为了让整个工作流自动化起来,需要结合一些任务调度平台,如Oozie,Linux cront...
Kylin构建Cube过程详解
[size=13.3333px]在使用Kylin的时候,最重要的一步就是创建cube的模型定义,即指定度量和维度以及一些附加信息,然后对cube进行build,当然我们也可以根据原始表中的某一个string字段(这个字段的格式必须是日期格式,表示日期的含义)设定分区字段,这样一个cube就可以进行多次build,每一次的build会生成一个segment,每一个segment对应着一个时间区间的c...
猜你喜欢
Kylin之Kafka流式构建
前提条件 1、Kylin将Kafka抽象成一个等同于Hive的数据源,也就是说Kylin是作为消费者从Kafka拉取数据的。因此Kylin需要依赖Kafka的客户端Jar包,因此我们需要设置环境变量KAFKA_HOME,指向kafka的客户端Jar的路径。 eg: export KAFKA_HOME=/usr/lib/kafka/client 2、写入Kafka中的数据为相同格式的JSON数据,K...
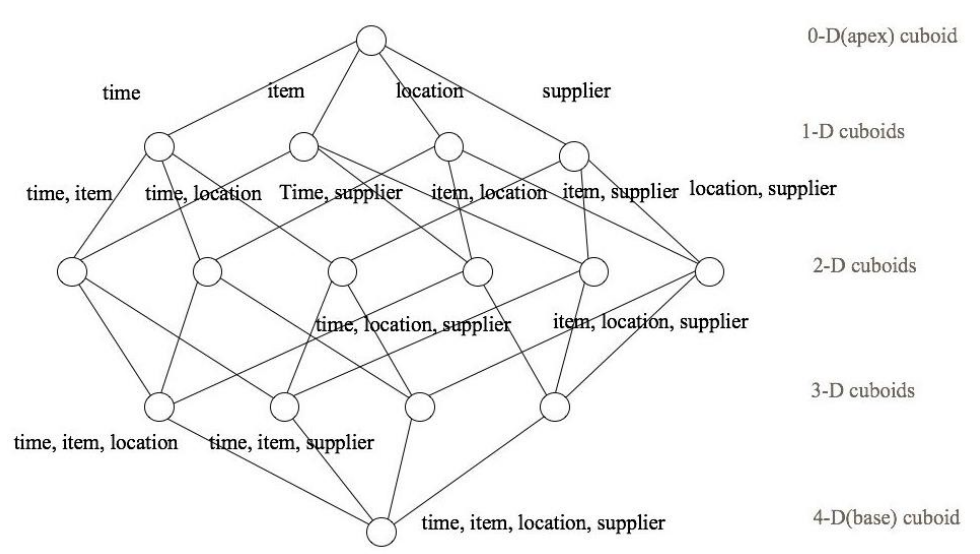
(48)Kylin Cube 构建原理
1 维度和度量 维度:即观察数据的角度。 比如员工数据,可以从性别角度来分析,也可以更加细化, 从入职时间或者地区的维度来观察。维度是一组离散的值,比如说性别中的男和女,或者时 间维度上的每一个独立的日期。因此在统计时可以将维度值相同的记录聚合在一起,然后应 用聚合函数做累加、平均、最大和最小值等聚合计算。 度量:即被聚合(观察)的统计值,也就是聚合运算的结果。 比如说员工数据中不同性 别员工的人...

Kylin Cube构建原理+调优
目录 Kylin Cube构建原理 维度和度量 Cube和Cuboid Cube构建算法 Cube存储原理 Kylin Cube构建优化 使用衍生维度(derived dimension) 使用聚合组(Aggregation group) Row Key优化 并发粒度优化 Kylin Cube构建原理 维度和度量 维度:即观察数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时...
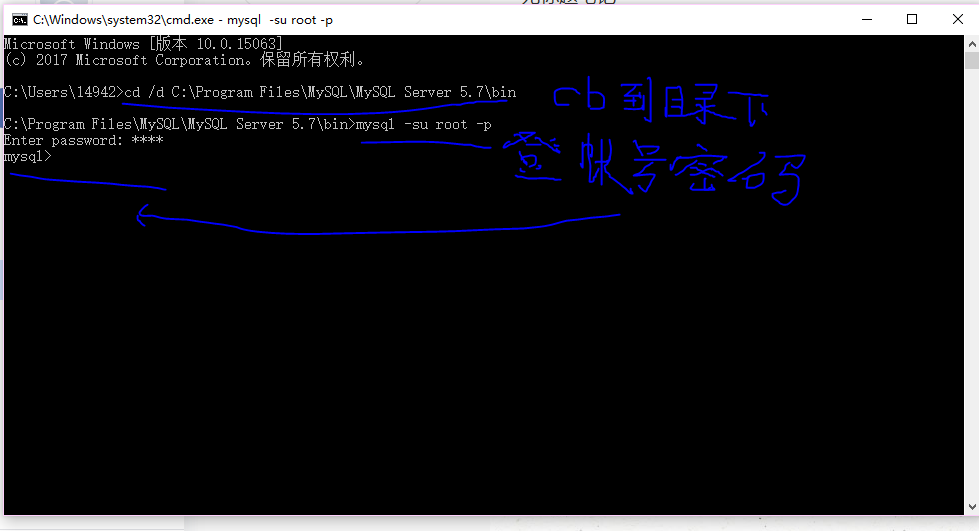
Mysql基本使用技巧
通过几天简单的学习,我掌握了一点基本的mysql操作步骤,下面是我的学习笔记,分享给大家,共同学习。我们都知道数据库在我们开发学习工作中必不可少,mysql作为一种被广泛使用的数据库,所以我们的学习必不可少。 使用mysql我们需要下载安装好所有的工具,在此我不在一一介绍,接下来,我们切入主题,MySQL的简单操作,下面是使用步骤。(我的所有步骤均是在windows下的命令行窗口完成的...
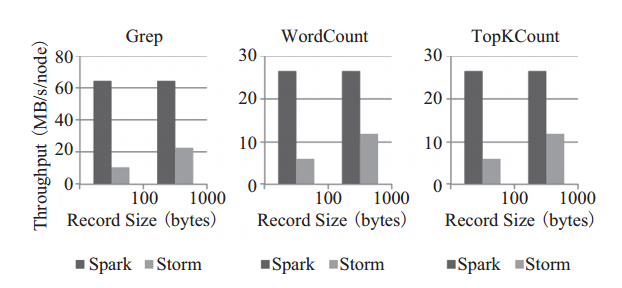
Apache Spark Streaming的优点
Apache Spark Streaming的优点: (1)优势及特点 1)多范式数据分析管道:能和 Spark 生态系统其他组件融合,实现交互查询和机器学习等多范式组合处理。 2)扩展性:可以运行在 100 个节点以上的集群,延迟可以控制在秒级。 3)容错性:使用 Spark 的 Lineage 及内存维护两份数据进行备份达到容错。 RDD通过 Lineage 记录下之前的操作,如果某节点在运...
问答精选
Python Regex Matching
I am inputting a text file (Line)(all strings). I am trying to make card_type to be true so it can enter the if statement, however, it never enters the IF statement. The output that comes out from the...
Can't insert this JSON data to SQL Server?
I'm trying to insert the following JSON data into a table on our SQL Server with python code. And if I could solve this with executing a SQL statement, I would be so happy. Because our Application ser...
Spring Instance Factory not working
I started learning spring recently and doing a simple demo of Instance factory but getting error. Java Bean: Interface: Factory: Spring config When I run the code by getting Bike Object from context, ...
How to track direct URL referrer
Most hosts come with softwares or google analytics which allows you to know how a person got to your site, for example: a link on yelp.com or a facebook.com page link. But it is impossible for the sof...
String range search over a RAW datatype
We are using an oracle table as a simple event store, in this table we are saving the message ids (.Net GUID using a SequentialGuidComb) as RAW(16). We are writing a consuming application which needs ...
相关问题
相关文章
热门文章
推荐文章
相关标签
推荐问答
- How do I calculate the difference of two alias for sorting
- Error using discord bot on my ubuntu server
- How to fix this JsonMappingException: N/A during XML deserialization
- RxJava's switchOnNext method does not behave as JavaDoc described
- Nested/inner classes in WCF?
- Return array from INDEX function in Excel?
- Powershell Invoke-RestMethod Paging
- Is select/poll keep checking for data during wait or just check once when data available?
- apache nifi: hive closes connection and workflows stop working
- Laravel 8 UniSharp File Manager 3 change base directory from app/storage to app/public