YOLOv3目标检测:训练自己的数据集
技术标签: 目标检测 YOLO YOLOv3 计算机视觉 深度学习

YOLOv3目标检测实战:交通标志识别
交通标志数据集、数据集格式转换、修改配置文件、训练LISA数据集、测试训练出的网络模型、性能统计(mAP计算和画出PR曲线)和先验框聚类。 YOLOv3可以实时地进行端到端的目标检测,以速度快见长。本课程将手把手地教大家使用YOLOv3实现交通标志识别。本课程的YOLOv3使用Darknet,在Ubuntu上做项目演示。 Darknet是使用C语言实现的轻型开源深度学习框架,依赖少,可移植性好,值得
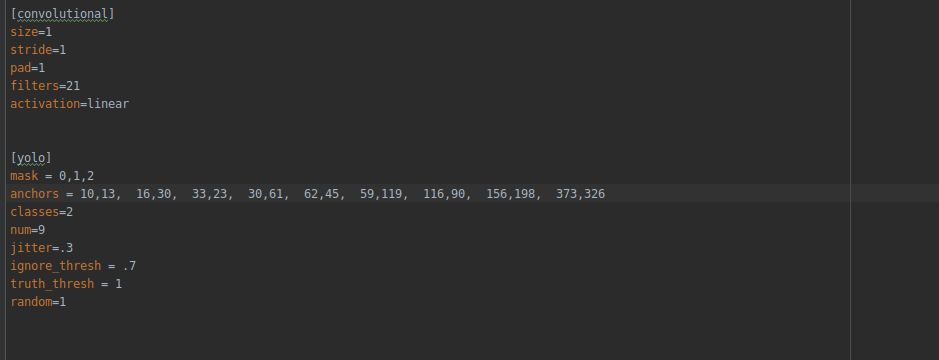
pytorch 版yolov3 详解
改为自己数据集的类别,并修改全卷积层的filter数目, 即yolo层的classes, 和convolutional 层的filters. 修改超参数,在使用yolov3进行训练时, 可根据自己的... 的图像拼接方法,随机选择四张图片,进行拼接,而后将拼接好的图像进行随机旋转、裁剪等操作,以扩充数据。 3 使用yolov3训练自己的数据集 首先,准备好自己的训练数据集,并生成yolov3训练
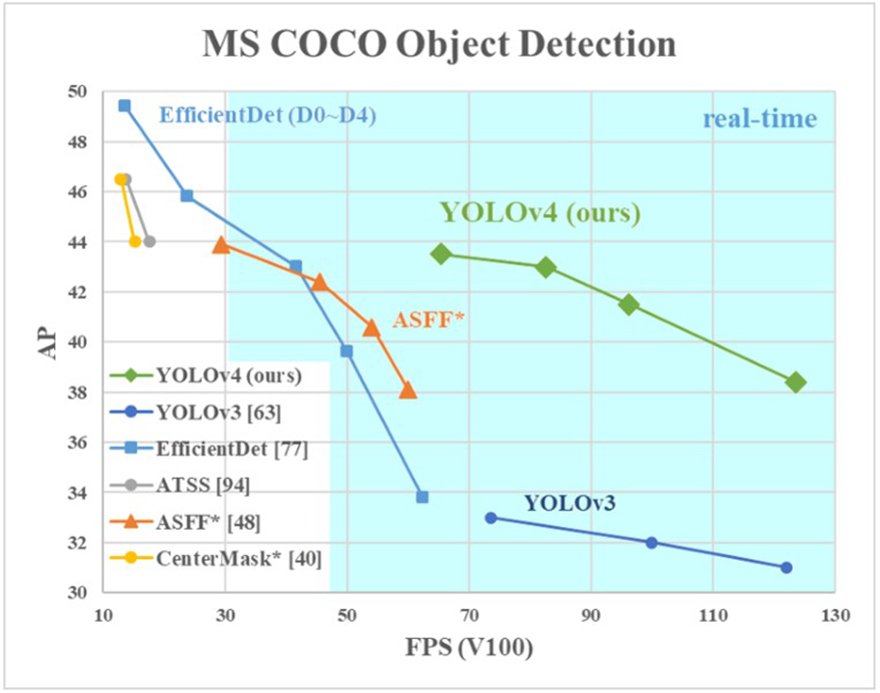
YOLOv4目标检测实战:训练自己的数据集
%和12%。 YOLO系列是基于深度学习的端到端实时目标检测方法。本课程将手把手地教大家使用labelImg标注和使用YOLOv4训练自己的数据集。课程实战分为两个项目:单目标检测(足球目标检测)和多目标检测(足球和梅西同时检测)。 本课程的YOLOv4使用AlexyAB/darknet,在Ubuntu系统上做项目演示。包括:安装YOLOv4、标注自己的数据集、整理自己的数据集、修改配置文件、训练
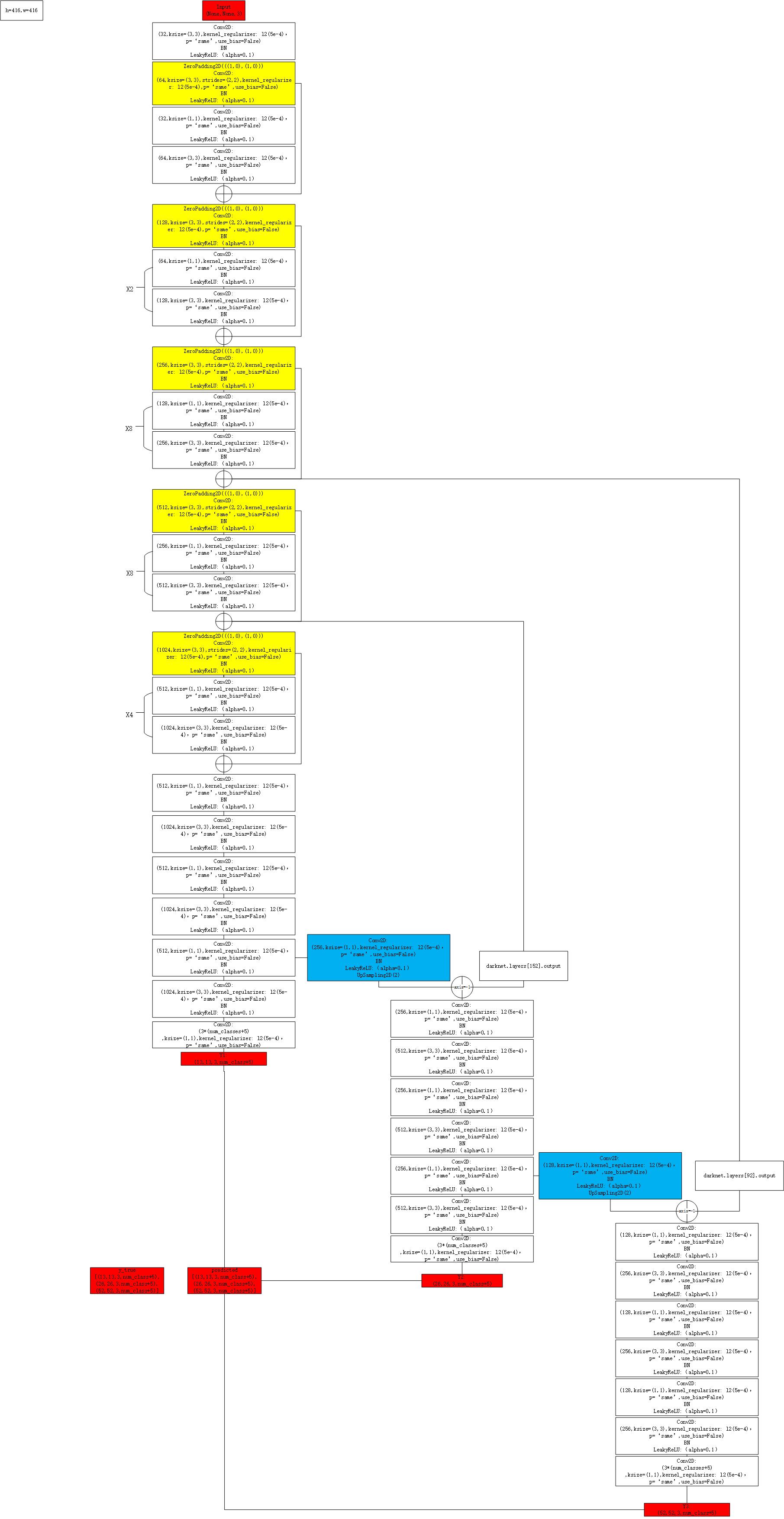
目标检测相关笔记(一)——YOLOv3代码梳理(keras版)
目标检测相关笔记(一)——YOLOv3代码梳理(keras版) 最近在整理之前总结的各种笔记,跟大家共同分享。本篇是基于keras版YOLOv3绘制的算法流程图,darknet以及pytorch类似,接下来有时间的话也会针对细节上的不同以及最后指标的差异进行进一步分析。 目前先贴上训练阶段的流程图,如有问题欢迎指正。 YOLOv3训练 模型结构 损失计算 YOLOv3训练
【目标检测】YOLOv3&YOLOv4学习过程
,还是自己看看视频比较好。 代码方面:如果你想用YOLOv3搭建一个自己的项目,可以按照这个博客进行修改,基于YOLOv3的目标检测分类,博客中有一个yolo.weight.h5文件可以在后面的链接中下...建议看原版的论文(也放在链接里)视频链接 视频里对理论和代码都有所讲解,如果想做到预测自己的数据集得出YOLOv3一样的结果和mAP值。可以自行根据上面YOLOv3博客中进行修改相应文件,我就只把我写
智能推荐

yolov3 训练自己的数据集!
3.1 配置cfg文件 3.1.1 复制yolov3.cfg(...\darknet-master\cfg目录下)文件并重命名为yolo-obj.cfg(或者其他名字,只要各处对应即可),复制到darknet.exe相同目录下(或者其他目录,输入命令时对应即可)。 &...
谷歌colab训练自己的数据集YOLOv3
自己电脑的GPU不支持cuda,所以尝试使用谷歌的Colabortory,免费提供GPU,最长运行时间12小时,因此一般需要挂载到谷歌云盘上,储存文件。 数据集 目标检测的数据集需要自己手动标注目标物体位置并对应生成xml文件表示目标框的位置,本文简单介绍windows系统下标注工具LabelImg的使用。 LabelImg下载链接:LabeIImg 下载好labelImg-master.zip后...
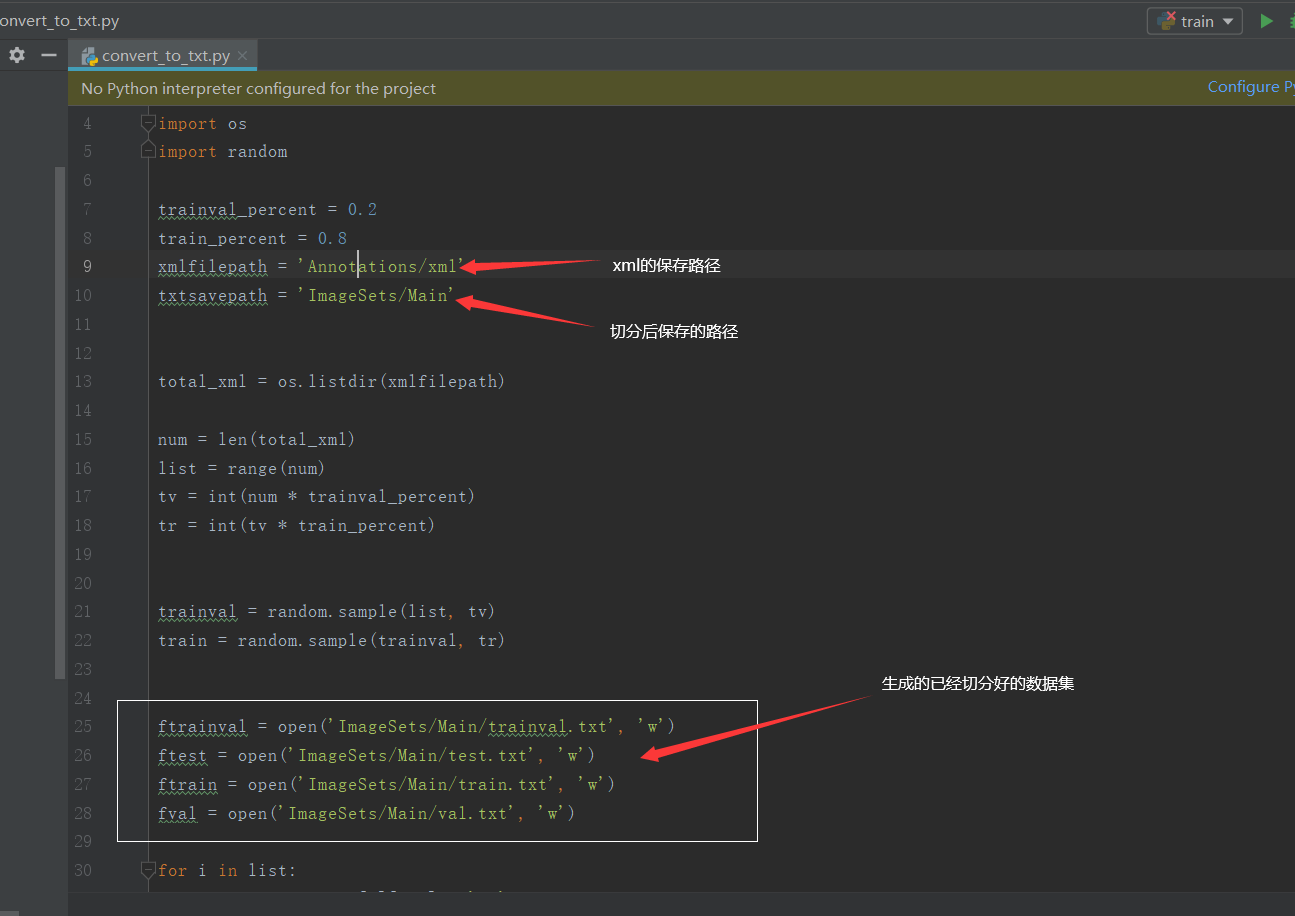
yolov3训练自己的数据集
yolov3训练自己的数据集 从图片和xml的保存,到训练 可能的报错 进行改进和防止报错 从图片和xml的保存,到训练 保存地址随便,但图片名,要和xml的命名对应。因为convert_to_txt.py文件是以xml的命名为切分,而voc_annotation.py文件是以convert_to_txt.py生成的文件来遍历生成文件。 下面是详细步骤: 1,图片保存 在convert_to_tx...
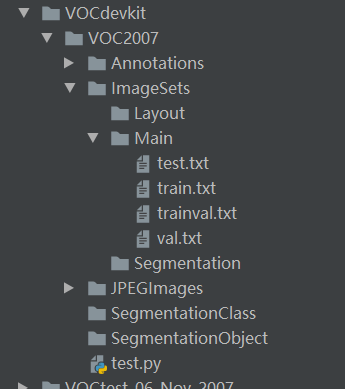
【深度学习】YOLOV3训练自己的数据集
在Github上下载代码: https://github.com/YunYang1994/tensorflow-yolov3.git 1.配置好相关的环境,其中Tensorflow==1.14.0版本 2.新建自己的数据集文件夹,其中图片数据集包括(Annotation和JPEGImage两个文件夹),新建文件夹目录如下: 3.改变data/classes/voc.name中类别; 4.在scri...

yolov3训练自己的数据
参考教程 https://blog.csdn.net/u012746060/article/details/81183006 注意测试的时候跑的是yolo.video程序 如果最后结果没有框,可以看下2007_train.txt,2007_val.txt,2007_test.txt的txt里面是不是有坐标,有坐标最后才会生成框 如果labellmg标定的框有浮点数最后也会导致一些错误记不太清了之前...
猜你喜欢
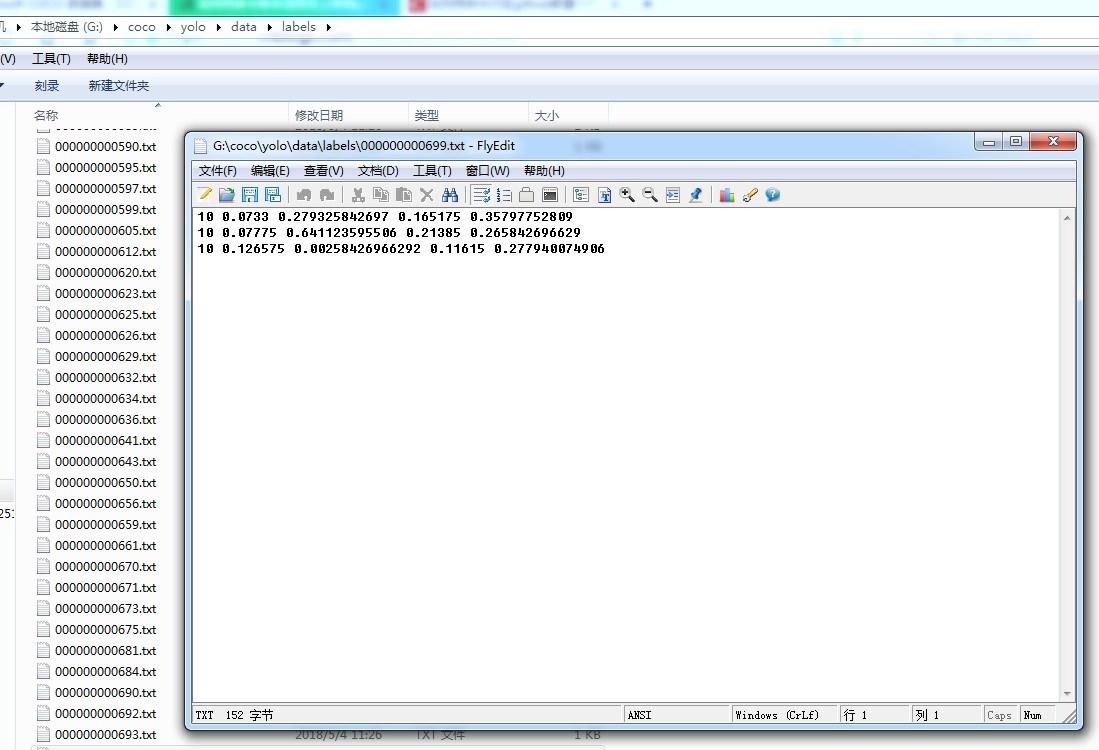
在Darknet环境下训练MS COCO 2017数据集(目标检测)(YOLOv3)
COCO 数据集是一个大型数据集,里面包含了包括 object detection, keypoints estimation, semantic segmentation,image caption 等多个任务所需要的图像数据及其标注信息。 以MS COCO 2017为例,一共 25G 左右的图片和 1.5G 左右的 annotation 文件,annotation 文件的格式为 .json 格...

yolov3训练自己的数据集(darknet)+visdrone数据集
踩了很多坑,分享一下自己训练的经历~ 我使用的visdrone数据集包含很多小目标,选择的darknet框架下的yolov3。也尝试了pytorch版本的不过刚开始效果不好,等的很着急后来放弃了,到后来才知道这个数据集现需要很长时间训练,我用的云服务器1080ti显卡,大概需要60个小时~~~ 数据集下载链接:https://www.jianshu.com/p/62e827306fca 。使用的V...
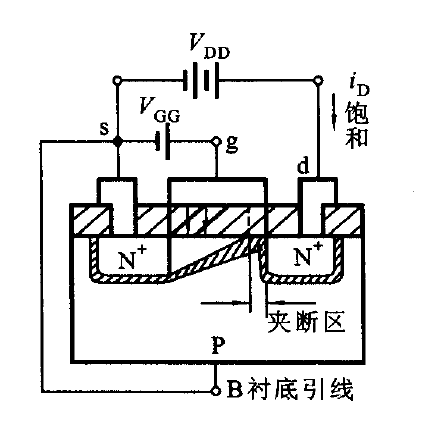
场效应管放大电路
金属-氧化物-半导体(MOS)场效应管 N沟道增强型MOSFET 栅源加电压,在电场作用下产生沟道。产生沟道的门限开启电压VT。 漏源加电压,产生电压梯度,导致沟道夹断。预夹断的临界条件 输出特性 特性方程 可变电阻区 &...

【响应式】foundation栅格布局的“尝鲜”与“填坑”
提到响应式,就不得不提两个响应式框架——bootstrap和foundation。在标题上我已经说明白啦,今天给大家介绍的是foundation框架。 何为“尝鲜”?就是带大伙初步一下foundation的灵活和强大 何为“踩坑”?就是我把我使用的时候踩过的坑给标个记号,这样大伙用的时候就可以“绕道而...

word2vec笔记
word2vec 词向量 one hot Distributed representation CBOW&Skip-Gram CBOW Skip-Gram sigmoid函数 Huffman树 基于Hierarchical Softmax的模型 基于Negative Sampling的模型 本文基于word2vec原理CBOW与Skip-Gram模型基础 CBOW与Skip-Gram的模型...
问答精选
SQL, update command not ending properly
It keeps saying : ORA-00933: SQL command not properly ended Pls help me or give me a link to a solution You can use a correlated subquery instead:...
How can I escape $.each loop with my data?
I'm doing an Json call to retrieve an a list of locations with information details for each location. longitude and latitude are included in this info. I am using Google's distance matrix api to get t...
How to display all the columns (and their type) in all tables of all schemas in a database?
Suppose you have a database which has an 'n' number of schemas with an 'n' number of tables each. Each of these contain an 'n' number of columns. How would I print all this data along with the data ty...
How to set the java.library.path in intelliJ Idea
Could anyone please help how do I solve this error: I am using IDEA IDE as a first time, and have been using Resin_4.0.37 as a server to test my work. As soon as I start my lcoal server in debug mode ...
How to calculate mouse coordinate based on resolution c#
i am trying to develop a remote desktop apps with c#. so i have couple of question regarding mouse coordinate calculation based on picture box suppose i have picture box and i want to capture mouse co...
相关问题
相关文章
热门文章
推荐文章
相关标签
推荐问答
- How do I convert this PHP regex to Javascript?
- Open MS Access with OLEDB connection string and not have access create the .ldb lock file
- Is it possible to install TensorFlow using Anaconda 2.1 on Windows XP(32 bit)?
- Why is (18446744073709551615 == -1) true?
- I get the same number with addition method?
- Use a stream as file?
- TextWrap AND TextTrimming in a "flying" grid
- Syntax error on adding multiple indexes on Table Creation mysql
- Spring MVC case insensitive URLs
- MySql Shared lookup table