Word Embedding
技术标签: 机器学习
简介
https://machinelearningmastery.com/what-are-word-embeddings/
https://www.zhihu.com/question/32275069
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
One of the benefits of using dense and low-dimensional vectors is computational: the majority of neural network toolkits do not play well with very high-dimensional, sparse vectors. … The main benefit of the dense representations is generalization power: if we believe some features may provide similar clues, it is worthwhile to provide a representation that is able to capture these similarities.
Algorithms
1. Embedding Layer
It requires that documents are clean and each words are encoded as one-hot. The size of vector space are specified as the part of the model, such as 50, 100, 300.
This approach of learning an embedding layer requires a lot of training data and can be slow, but will learn an embedding both targeted to the specific text data and the NLP task.
每一个单词都需要一个one-hot vector, 计算量大,单词之间相关性没有被表示。

As we can look at following picture, word ‘girl’ won’t make any help of the training of other words in the first layer.
2. Word2Vec
paper: Linguistic Regularities in Continuous Space Word Representations, 2013.
It is good at capturing syntactic and semantic regularities in language.
Two different learning models were introduced that can be used as part of Word2Vec approach to learn word embedding.
- Continuous Bag-of-Words, or CBOW model. # 通过已知的周围词对该词进行word embedding.
- Continuous Skip-Gram Model. # 通过预测周围词进行 word embbeding.

3. GloVe
paper: GloVe: Global Vectors for Word Representation, 2014.
把全局统计(eg. Latent Semantic Analysis (LSA)) 和局部文本学习 (word2vec) 结合起来,更加有效
The Globe Vector for Word Representation. It is an extension to word2vec and can learn word vector more efficiently.
Classical vector space model representations of words were developed using matrix factorization techniques such as Latent Semantic Analysis (LSA) that do a good job of using global text statistics but are not as good as the learned methods like word2vec at capturing meaning and demonstrating it on tasks like calculating analogies (e.g. the King and Queen example above).
GloVe is an approach to marry both the global statistics of matrix factorization techniques like LSA with the local context-based learning in word2vec.
Rather than using a window to define local context, GloVe constructs an explicit word-context or word co-occurrence matrix using statistics across the whole text corpus. The result is a learning model that may result in generally better word embeddings.
How to use the word embedding
1. Learn an Embedding
You may choose to learn a word embedding for your problem.
This will require a large amount of text data to ensure that useful embeddings are learned, such as millions or billions of words.
You have two main options when training your word embedding:
- Learn it Standalone, where a model is trained to learn the embedding, which is saved and used as a part of another model for your task later. This is a good approach if you would like to use the same embedding in multiple models.
- Learn Jointly, where the embedding is learned as part of a large task-specific model. This is a good approach if you only intend to use the embedding on one task.
2. Reuse an Embedding
It’s common for researcher to use pre-trained word embbeding. For example, both word2vec and GloVe word embeddings are available for free download.
These can be used on your project instead of training your own embeddings from scratch.
可以选择直接使用,也可以基于此进行更新。
Articles
- Word embedding on Wikipedia
- Word2vec on Wikipedia
- GloVe on Wikipedia
- An overview of word embeddings and their connection to distributional semantic models, 2016.
- Deep Learning, NLP, and Representations, 2014.
Papers
- Distributional structure, 1956.
- A Neural Probabilistic Language Model, 2003.
- A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, 2008.
- Continuous space language models, 2007.
- Efficient Estimation of Word Representations in Vector Space, 2013
- Distributed Representations of Words and Phrases and their Compositionality, 2013.
- GloVe: Global Vectors for Word Representation, 2014.
Projects
Word2Vec 算法
obal Vectors for Word Representation](https://nlp.stanford.edu/projects/glove/)
Word2Vec 算法
来源:网络
智能推荐
Word Embedding in Tensorflow
嵌入层可以理解为一个查询表,它从整数索引(表示特定单词)映射到稠密向量(它们的嵌入向量)。嵌入的维数是一个超参数,您可以用它来试验看看什么对您的问题有效,这与您在稠密层中试验神经元的数量非常相似。 注意: 嵌入层只能当做输入层. 创建嵌入层时,嵌入的权重是随机初始化的(与任何其他层一样)。在训练过程中,通过反向传播逐步调整。一旦训练好了,习得的单词嵌入将大致编码单词之间的相似性(因为它们是针对您的...
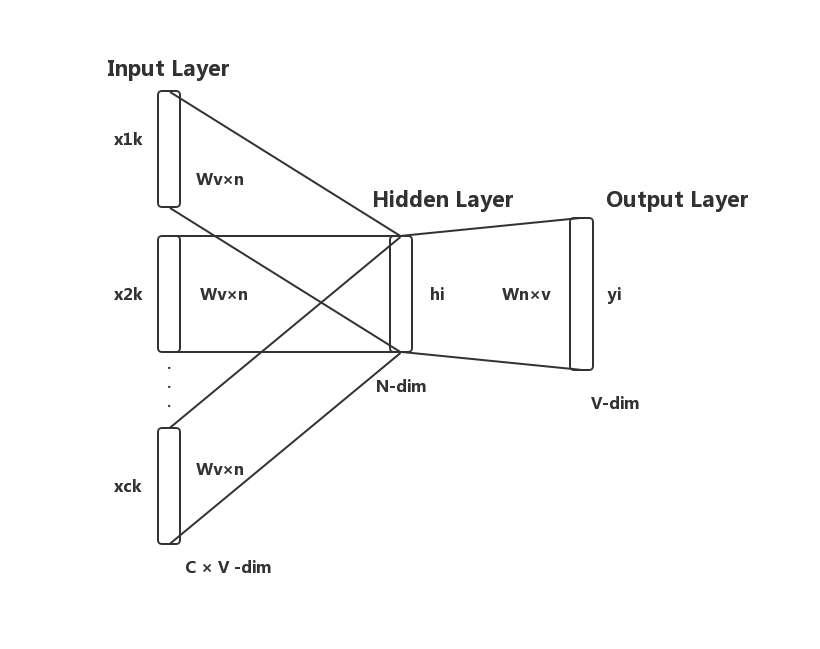
Word Embedding 学习笔记
Word Embedding 学习笔记——GloVe 与 word2vec 完成日期:2019.02.25 文章目录 Word Embedding 学习笔记——GloVe 与 word2vec 一. Word Representation 二. One-hot Encoding 三. Word Embedding 3.1 Word Embedding...
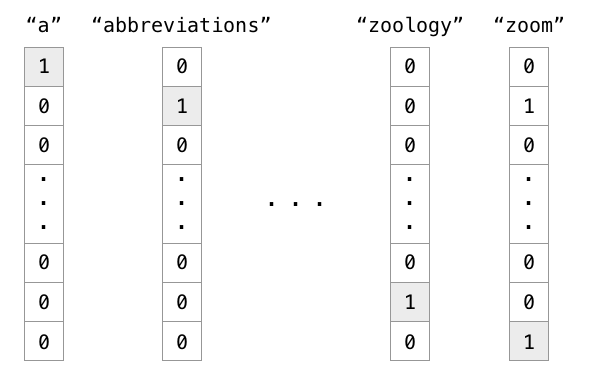
word embedding词嵌入
word embedding词嵌入 One hot representation Distributed representation 神经网络分析 Word embedding 训练方法 word embedding的功能一般提现在文字序列预测中,比如存在于LSTM网络中。它的功能类同将图片在计算机中以像素的存储方式一样,对序列中的每一个元素进行编码,形成自己的表达序列的独特方式。 序列中表达单...
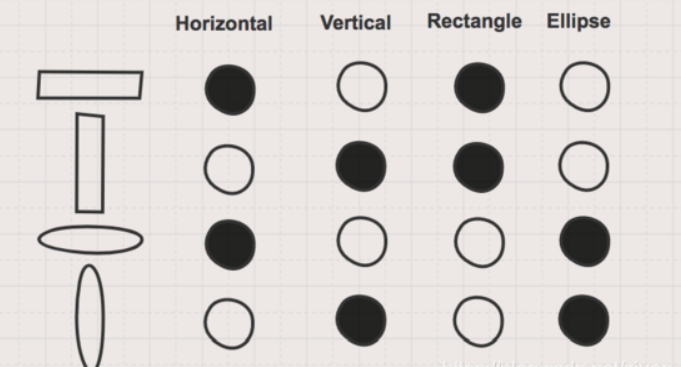
Word Embedding的学习
Word Embedding的概述: 根据之前对One Hot的介绍,我们发现它不能够表现出词语之间的相似度,因此提出Word Embedding。 首先,我们提一下分布式表示(distributed representation):若干元素的连续表现形式,将词的语义分布式地存储在各个维度中,与之相反的是独热向量(One Hot)。 而Word Embedding(词嵌入)是基于神经网络的分布式表...
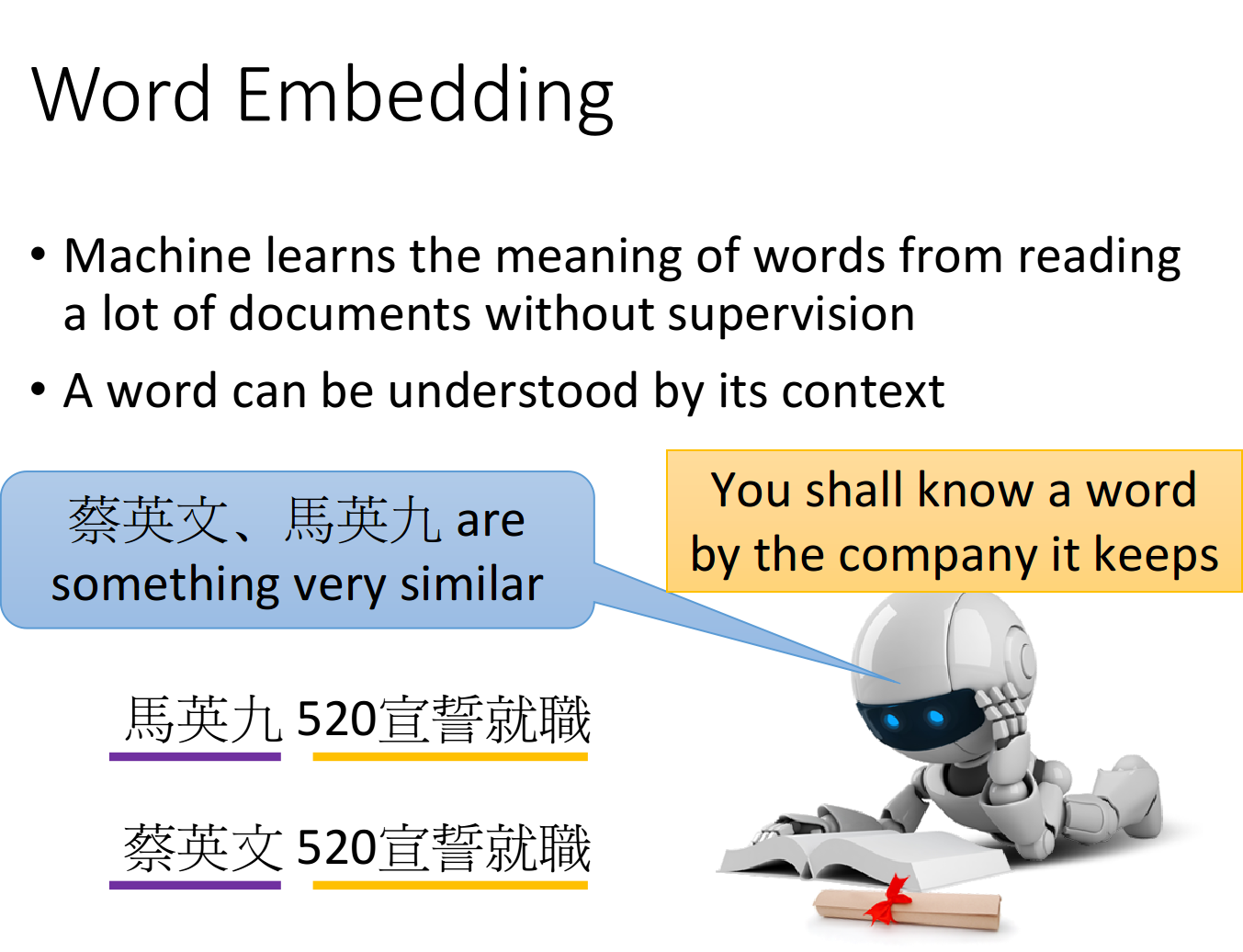
Unsupervised Learning: Word Embedding
Unsupervised Learning: Word Embedding 本文介绍NLP中词嵌入(Word Embedding)相关的基本知识,基于降维思想提供了count-based和prediction-based两种方法,并介绍了该思想在机器问答、机器翻译、图像分类、文档嵌入等方面的应用 因为敏感词原因,文章中有些文字用拼音代替。。。 Introduction 词嵌入(word embed...
猜你喜欢

1. Word Embedding
Word Embedding(将文本转换成适用于计算机的语言) 机器无法直接理解输入的文本信息,所以需要先将文本信息转换成机器可以读懂的语言,这就涉及到编码部分 - - word embedding。 Word embedding的主流有两种: (https://blog.csdn.net/savinger/article/details/89308831) (1)基于频率的Word embedd...
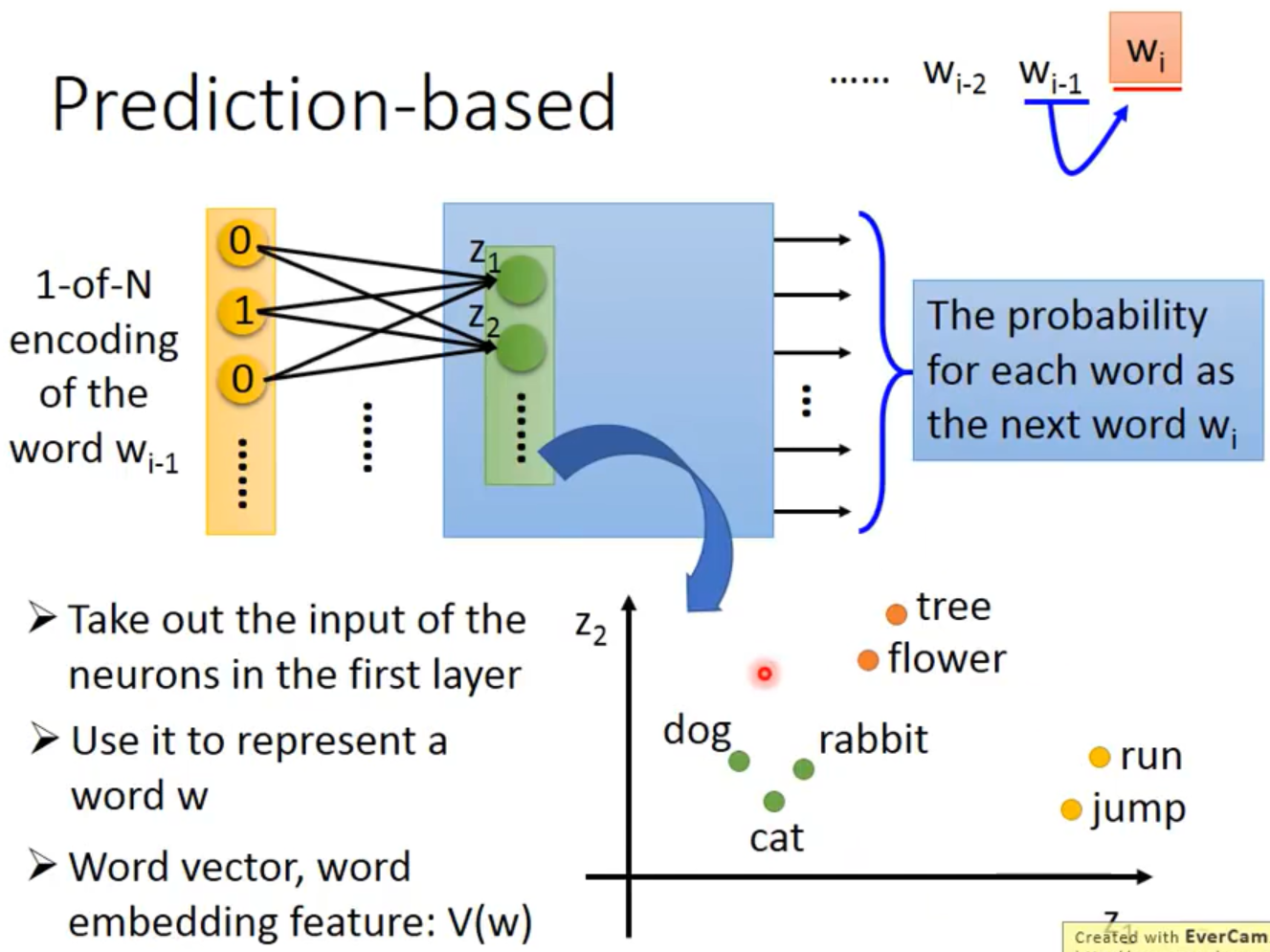
NLP-Word Embedding
Word Embedding(字嵌入):把一个单词转化为向量表示。 最经典的做法是使用one-hot表示法。向量中只有一个1,其余全是0.字典有多少单词,向量就有多少维。它的特点是单词之间没有关联。 &nbs...
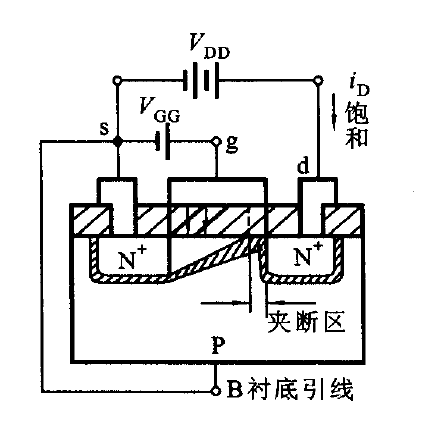
场效应管放大电路
金属-氧化物-半导体(MOS)场效应管 N沟道增强型MOSFET 栅源加电压,在电场作用下产生沟道。产生沟道的门限开启电压VT。 漏源加电压,产生电压梯度,导致沟道夹断。预夹断的临界条件 输出特性 特性方程 可变电阻区 &...

【响应式】foundation栅格布局的“尝鲜”与“填坑”
提到响应式,就不得不提两个响应式框架——bootstrap和foundation。在标题上我已经说明白啦,今天给大家介绍的是foundation框架。 何为“尝鲜”?就是带大伙初步一下foundation的灵活和强大 何为“踩坑”?就是我把我使用的时候踩过的坑给标个记号,这样大伙用的时候就可以“绕道而...

word2vec笔记
word2vec 词向量 one hot Distributed representation CBOW&Skip-Gram CBOW Skip-Gram sigmoid函数 Huffman树 基于Hierarchical Softmax的模型 基于Negative Sampling的模型 本文基于word2vec原理CBOW与Skip-Gram模型基础 CBOW与Skip-Gram的模型...
问答精选
SQL, update command not ending properly
It keeps saying : ORA-00933: SQL command not properly ended Pls help me or give me a link to a solution You can use a correlated subquery instead:...
How can I escape $.each loop with my data?
I'm doing an Json call to retrieve an a list of locations with information details for each location. longitude and latitude are included in this info. I am using Google's distance matrix api to get t...
How to display all the columns (and their type) in all tables of all schemas in a database?
Suppose you have a database which has an 'n' number of schemas with an 'n' number of tables each. Each of these contain an 'n' number of columns. How would I print all this data along with the data ty...
How to set the java.library.path in intelliJ Idea
Could anyone please help how do I solve this error: I am using IDEA IDE as a first time, and have been using Resin_4.0.37 as a server to test my work. As soon as I start my lcoal server in debug mode ...
How to calculate mouse coordinate based on resolution c#
i am trying to develop a remote desktop apps with c#. so i have couple of question regarding mouse coordinate calculation based on picture box suppose i have picture box and i want to capture mouse co...
相关问题
- License problem embedding Mono?
- PHP embedding in HTML problem
- Embedding one cmake project inside of another?
- Embedding Video Cross Browser, Single format / Embed
- embedding_lookup_sparse的奇怪输出
- 如何从Scikit-Engres Embedding解码?
- flops for tf.embedding_lookup_sparse.
- Tensorflow如何实现embedding_column?
- Is PIA embedding broken in .NET 4.0 beta 2?
- Windows Mobile 6.1 - .NET CF StatusBar control - embedding icon
相关文章
热门文章
推荐文章
相关标签
推荐问答
- How do I convert this PHP regex to Javascript?
- Open MS Access with OLEDB connection string and not have access create the .ldb lock file
- Is it possible to install TensorFlow using Anaconda 2.1 on Windows XP(32 bit)?
- Why is (18446744073709551615 == -1) true?
- I get the same number with addition method?
- Use a stream as file?
- TextWrap AND TextTrimming in a "flying" grid
- Syntax error on adding multiple indexes on Table Creation mysql
- Spring MVC case insensitive URLs
- MySql Shared lookup table