【优化算法】一文搞懂RMSProp优化算法
在前面我们讲了AdaGrad算法,见下:
忆臻:Deep Learning 最优化方法之AdaGradzhuanlan.zhihu.com而本文要介绍的RMSProp优化算法是AdaGrad算法的一种改进。
首先给出AdaGrad算法:
再抛出原始的RMSProp算法:
可以看出RMSProp优化算法和AdaGrad算法唯一的不同,就在于累积平方梯度的求法不同。RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。见下:
至于为什么加了一个系数 之后,作用相当于加了一个衰减系数来控制历史信息的获取多少,可以参考我下面这篇文章:
好,下面先给出结论【来自好友YBB的总结】:
1.AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
2.经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
相比于AdaGrad的历史梯度:
RMSProp增加了一个衰减系数来控制历史信息的获取多少:
直观理解作用
简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以经过衰减系数控制的历史梯度平方和的平方根,使得每个参数的学习率不同
那么它起到的作用是什么呢?
起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
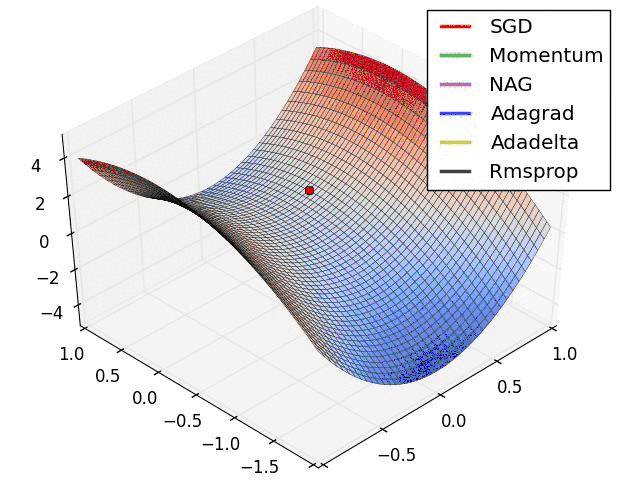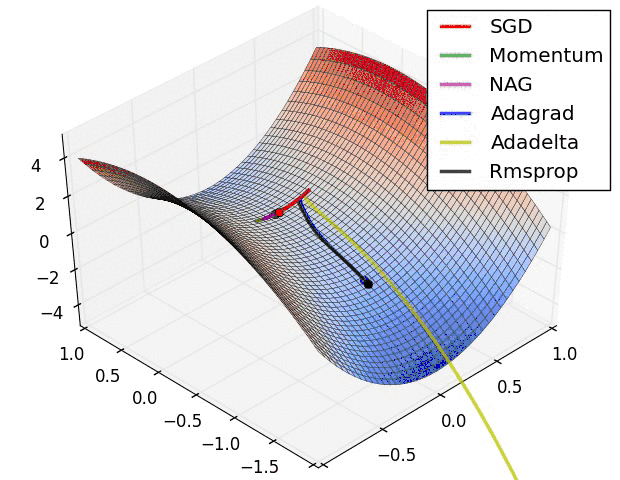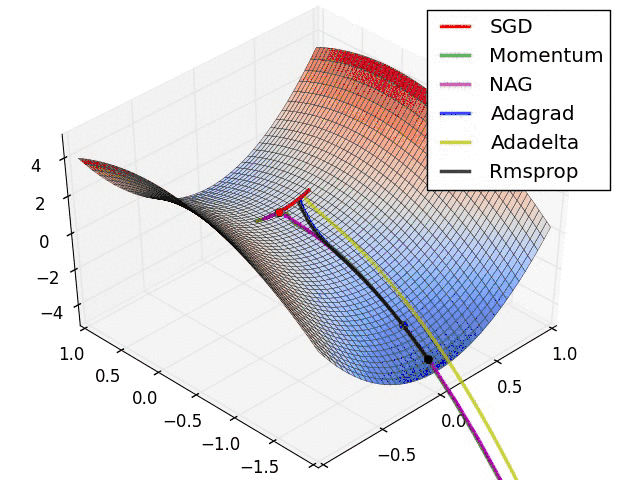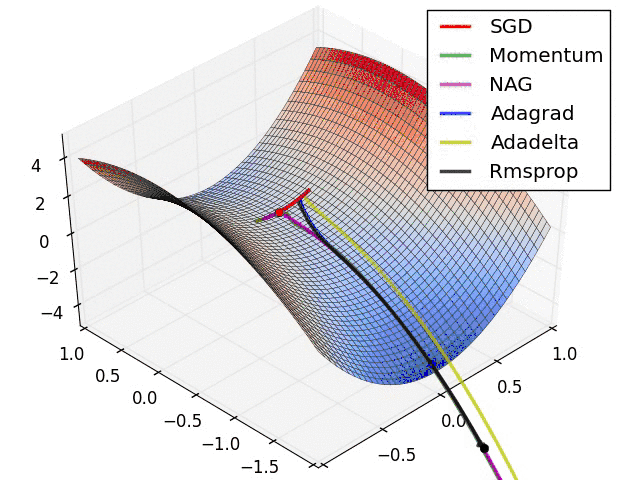
下面通过例子讲解一下:
假设我们现在采用的优化算法是最普通的梯度下降法mini-batch。它的移动方向如下面蓝色所示:
假设我们现在就只有两个参数w,b,我们从图中可以看到在b方向走的比较陡峭,这影响了优化速度。
而我们采取AdaGrad算法之后,我们在算法中使用了累积平方梯度:
从上图可以看出在b方向上的梯度g要大于在w方向上的梯度。
那么在下次计算更新的时候,r是作为分母出现的,越大的反而更新越小,越小的值反而更新越大,那么后面的更新则会像下面绿色线更新一样,明显就会好于蓝色更新曲线。
在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
这就是RMSProp优化算法的直观好处。
参考:
http://blog.csdn.net/bvl10101111/article/details/72616378blog.csdn.net吴恩达老师slides





2 条评论
图是Ng课件上的吧
是的呢