浅谈KL散度
技术标签: Basis
浅谈KL散度
一、第一种理解
相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information divergence),信息增益(information gain)。
KL散度是两个概率分布P和Q差别的非对称性的度量。
KL散度是用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的比特个数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
根据shannon的信息论,给定一个字符集的概率分布,我们可以设计一种编码,使得表示该字符集组成的字符串平均需要的比特数最少。假设这个字符集是X,对x∈X,其出现概率为P(x),那么其最优编码平均需要的比特数等于这个字符集的熵:
H(X)=∑x∈XP(x)log[1/P(x)]
在同样的字符集上,假设存在另一个概率分布Q(X)。如果用概率分布P(X)的最优编码(即字符x的编码长度等于log[1/P(x)]),来为符合分布Q(X)的字符编码,那么表示这些字符就会比理想情况多用一些比特数。KL-divergence就是用来衡量这种情况下平均每个字符多用的比特数,因此可以用来衡量两个分布的距离。即:
DKL(Q||P)=∑x∈XQ(x)[log(1/P(x))] - ∑x∈XQ(x)[log[1/Q(x)]]=∑x∈XQ(x)log[Q(x)/P(x)]
由于-log(u)是凸函数,因此有下面的不等式
DKL(Q||P) = -∑x∈XQ(x)log[P(x)/Q(x)] = E[-logP(x)/Q(x)] ≥ -logE[P(x)/Q(x)] = - log∑x∈XQ(x)P(x)/Q(x) = 0
即KL-divergence始终是大于等于0的。当且仅当两分布相同时,KL-divergence等于0。
===========================
举一个实际的例子吧:比如有四个类别,一个方法A得到四个类别的概率分别是0.1,0.2,0.3,0.4。另一种方法B(或者说是事实情况)是得到四个类别的概率分别是0.4,0.3,0.2,0.1,那么这两个分布的KL-Distance(A,B)=0.1*log(0.1/0.4)+0.2*log(0.2/0.3)+0.3*log(0.3/0.2)+0.4*log(0.4/0.1)
这个里面有正的,有负的,可以证明KL-Distance()>=0.
从上面可以看出, KL散度是不对称的。即KL-Distance(A,B)!=KL-Distance(B,A)
KL散度是不对称的,当然,如果希望把它变对称,
Ds(p1, p2) = [D(p1, p2) + D(p2, p1)] / 2.
二、第二种理解
今天开始来讲相对熵,我们知道信息熵反应了一个系统的有序化程度,一个系统越是有序,那么它的信息熵就越低,反之就越高。下面是熵的定义
如果一个随机变量的可能取值为
,对应的概率为
,则随机变量
的熵定义为
有了信息熵的定义,接下来开始学习相对熵。
1. 相对熵的认识
相对熵又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度(即KL散度)等。设和
是取值的两个概率概率分布,则
对
的相对熵为
在一定程度上,熵可以度量两个随机变量的距离。KL散度是两个概率分布P和Q差别的非对称性的度量。KL散度是
用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。 典型情况下,P表示数据的真实分布,Q
表示数据的理论分布,模型分布,或P的近似分布。
2. 相对熵的性质
相对熵(KL散度)有两个主要的性质。如下
(1)尽管KL散度从直观上是个度量或距离函数,但它并不是一个真正的度量或者距离,因为它不具有对称性,即
(2)相对熵的值为非负值,即
在证明之前,需要认识一个重要的不等式,叫做吉布斯不等式。内容如下
3. 相对熵的应用
相对熵可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的相对熵为零,当两个随机分布的差别增
大时,它们的相对熵也会增大。所以相对熵(KL散度)可以用于比较文本的相似度,先统计出词的频率,然后计算
KL散度就行了。另外,在多指标系统评估中,指标权重分配是一个重点和难点,通过相对熵可以处理。
4.交叉熵与相对熵
参考:http://www.cnblogs.com/hxsyl/p/4910218.html
https://www.zhihu.com/question/41252833
ELBO(证据下界)
网上关于ELBO的内容较少,主要常出现在变分推断当中。
例如在用EM处理LDA主题模型时,
看看文档数据的对数似然函数 如下,为了简化表示,用
代替
,用来表示
对于变分分布
的期望。
其中,从第(5)式到第(6)式用到了Jensen不等式:
一般把第(7)式记为:
由于 是我们的对数似然的一个下界(第6式),所以这个L一般称为ELBO(Evidence Lower BOund)。那么这个ELBO和我们需要优化的的KL散度有什么关系呢?注意到:
在(10)式中,由于对数似然部分和我们的KL散度无关,可以看做常量,因此我们希望最小化KL散度等价于最大化ELBO。那么我们的变分推断最终等价的转化为要求ELBO的最大值。现在我们开始关注于极大化ELBO并求出极值对应的变分参数λ,ϕ,γ。
来源:https://www.cnblogs.com/yifdu25/p/8278986.html
智能推荐

《KL散度、WGAN、VAE》
KL散度 KL 散度是根据两个概率分布的表达式来算它们的相似度的。 WGAN相对于原始GAN 1.判别器最后一层去掉sigmoid 2.生成器和判别器的loss不取log 3.每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c 4.不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行 VAE VAE的Encoder尽量向正态分布看齐。 对抗的原理...
KL散度(信息熵)
对于离散型随机变量,信息熵公式如下: 对于连续型随机变量,信息熵公式如下: 注意,我们前面在说明的时候log \loglog是以2为底的,但是一般情况下在神经网络中,默认以e ee为底,这样算出来的香农信息量虽然不是最小的可用于完整表示事件的比特数,但对于信息熵的含义来说是区别不大的。其实只要这个底数是大于1的,都能用来表达信息熵的大小。 本篇我们来看看机器学习中比较重要的一个概念&mdash...

KL散度,JS散度,余弦距离,欧式距离
散度:量化两种概率分布P和Q之间差异的方式;相当于衡量两个函数之间的关系 GAN是最小化JS散度 VAE是最小化KL散度 KL散度(不对称):设p为随机变量X的概率分布,即p(x)为随机变量X在X=x处的概率密度函数值。两个概率分布p和q的KL散度(Kullback–Leibler divergence)也称为相对熵,用于刻画概率分布q拟合概率分布p的程度。 JS散度(对称): 距离:...

交叉熵、KL散度、Jeffery分歧、JS散度
D_{JS}(P||Q)=(1/2)*D_{KL}(P||(P+Q)/2)+(1/2)*D_{KL}(Q||(P+Q)/2) DJS(P∣∣Q)=(1/2)&low...
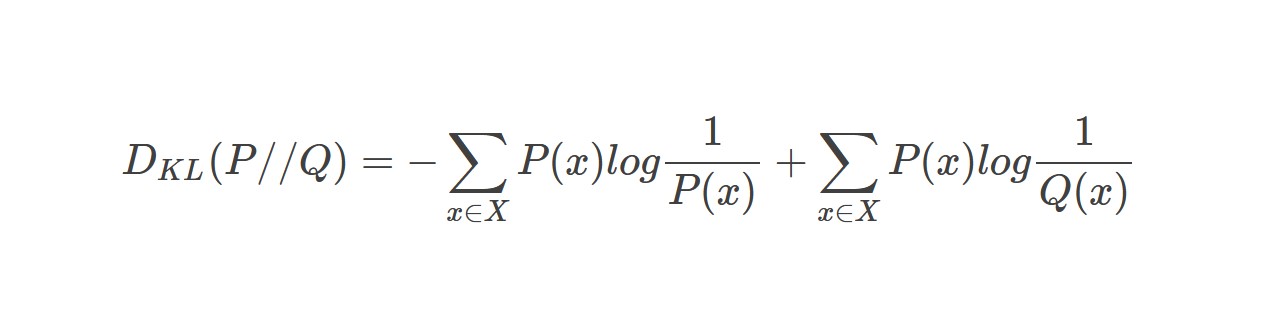
KL散度、JS散度、Wasserstein距离
KL散度、JS散度、Wasserstein距离 一、KL 散度 二、JS 散度 三、Wasserstein距离 一、KL 散度 KL散度又称为相对熵,信息散度,信息增益。KL散度是两个概率分布 P 和 Q 差别的非对称性的度量,如果两个分布 P 、Q 离得很远,完全没有重叠的时候,那么KL散度值是没有意义的。 KL散度是用来度量使用基于 “Q的编码” 来编码来自 &ldqu...
猜你喜欢

交叉熵与KL散度
参考文献 1.对数损失函数(Logarithmic Loss Function)的原理和 Python 实现 2.交叉熵与KL散度 3.深度学习剖根问底:交叉熵和KL散度的区别 4.详解机器学习中的熵、条件熵、相对熵和交叉熵 5.为什么交叉熵(cross-entropy)可以用于计算代价? 6.机器学习中的基本问题——log损失与交叉熵的等价性 核心:KL散度=交叉熵-熵 ...

交叉熵与KL散度
Welcome To My Blog 老遇到交叉熵作为损失函数的情况,于是总结一下 KL散度 交叉熵从KL散度(相对熵)中引出,KL散度(Kullback-Leibler Divergence)公式为: KL散度是衡量两个分布之间的差异大小的,KL散度大于等于0,并且越接近0说明p与q这两个分布越像,当且仅当p与q相等时KL散度取0. 交叉熵 在机器学习的分类问题中,常以交叉熵作为损失函数,此时同...
KL散度(Kullback-Leibler_divergence)
KL-divergence,俗称KL距离,常用来衡量两个概率分布的距离。 1. 根据shannon的信息论,给定一个字符集的概率分布,我们可以设计一种编码,使得表示该字符集组成的字符串平均需要的比特数最少。假设这个字符集是X,对x∈X,其出现概率为P(x),那么其最优编码平均需要的比特数等于这个字符集的熵: a.当log以2为底的时候称之为 bits,结果可以视为多少个二进制位可以表示该...
原型对象,原型链
函数都有prototype属性,它指向原型对象。 实例对象有__proto__属性,它指向对象原型 每一个原型对象都有constructor输赢,指向构造函数,每一个原型对象又具有__proto__属性,这个指向Object.prototype.在这里插入图片描述...

Node 调用 dubbo 服务的探索及实践
2.Dubbo简介 2.1 什么是dubbo Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。 2.2 流程图 Provider : 暴露服务的服务提供方。 Consumer : 调用远程服务的服务消费方。 Registry : 服务注册与发现的注册中心。 Monito...
问答精选
Correctly formatting GCM notifications?
I'm currently trying out the google cloud messaging service with its sample application "Guestbook." https://developers.google.com/cloud/samples/mbs/ I'm attempting to send notifications tha...
Are there any performance benefits of using Asynchronous functions over Synchronous in Node Js?
Now I came across an article that distinguishes between an Asynchronous function and Synchronous functions. From my understanding of the different examples and explanations, synchronous functions are ...
Python: Costing calculator output
Good day all I'm busy creating a small costing calculator for the signage department. I'm not getting the calculator to output the amount. Brief Description: You enter the height and width and then wh...
Flask-SQLAlchemy - model has no attribute 'foreign_keys'
I have 3 models created with Flask-SQLalchemy: User, Role, UserRole role.py: user.py: user_role.py: If I try (in the console) to get all users via User.query.all() I get AttributeError: 'NoneType' obj...
Seeding many PRNGs, then having to seed them again, what is a good quality approach?
I have many particles that follow an stochastic process in parallel. For each particle, there is a PRNG associated to it. The simulation must go through many repetitions to get average results. For ea...
相关问题
相关文章
热门文章
推荐文章
相关标签
推荐问答
- ShareActionProvider with background processing
- gridview changing position automatically when notifiedDatasetChangedCalled?
- How to efficiently fill-in a structure with vectors?
- when i exit from node js, i just cant give command in my terminal
- How to upload an image with Spray?
- Edit my message before posting in Twitter with Twitter API and PHP
- Using css style selector in JQuery not working?
- Can Html.Display/Html.DisplayFor/Html.DisplayForModel work with a DataTable?
- What does <?!= mean in Google Apps Script?
- Python/Linux - Manually installing httplib2 as a non-root user