如何保留ID之后的数据平衡技术,例如Rose,Smote
df1 = data.frame(id=c('A1','2','B3','4','5','6','7','8','9','10'),s1c1=c(0,0.2,0,0.5,0.8,0,0,0,0,0),s1c2=c(0,0,0.3,0,0,0.9,0.3,0,0,0),s1c3=c(0.1,0,0,0,0,0,0,0.2,0.8,0.1))
df2 = data.frame(id=c('A1','2','B3','4','5','6','7','8','9','10'),s2c1=c(0,0.22,0,0.35,0.8,0,0,0,0,0),s2c2=c(0,0,0.23,0,0,0.7,0.3,0,0,0),s2c3=c(0.2,0,0,0,0,0,0,0.4,0.9,0.4))
df <- merge(df1,df2, by="id",all=TRUE)
df$class <- c(0,0,0,0,0,1,1,0,0,0)
> df
id s1c1 s1c2 s1c3 s2c1 s2c2 s2c3 class
10 0.0 0.0 0.1 0.00 0.00 0.4 0
2 0.2 0.0 0.0 0.22 0.00 0.0 0
4 0.5 0.0 0.0 0.35 0.00 0.0 0
5 0.8 0.0 0.0 0.80 0.00 0.0 0
6 0.0 0.9 0.0 0.00 0.70 0.0 0
7 0.0 0.3 0.0 0.00 0.30 0.0 1
8 0.0 0.0 0.2 0.00 0.00 0.4 1
9 0.0 0.0 0.8 0.00 0.00 0.9 0
A1 0.0 0.0 0.1 0.00 0.00 0.2 0
B3 0.0 0.3 0.0 0.00 0.23 0.0 0
我正在使用玫瑰函数来生成样品以实现不平衡数据。但是,我想为Rose之后的DF保留DF的每个观察ID。使用玫瑰后,我要低于输出。
df.rose <- ROSE(class ~ ., data=df, seed=123,N=20,p=0.25)$data
> df.rose
id s1c1 s1c2 s1c3 s2c1 s2c2 s2c3 class
B3 -0.24636399 0.513435064 -0.0844105623 0.04695640 0.419960189 0.08112992 0
9 -0.05029030 0.199689698 0.7022285344 0.08255245 -0.133951228 1.16820765 0
9 -0.23671562 0.167377715 0.9634146745 -0.10923003 -0.129948534 1.00641398 0
B3 -0.16816685 0.434632663 -0.0174671002 -0.07245581 0.423706144 -0.07969934 0
9 -0.14420654 -0.015047974 0.8530741203 -0.22148879 -0.053786877 1.18091542 0
9 -0.38914709 -0.074365870 0.7940190162 -0.23306056 -0.230564666 1.14293933 0
6 0.19329086 0.807524478 -0.0089820194 0.06600218 0.734243934 0.13409831 0
6 0.03538563 0.731147735 0.2867432037 0.09746303 0.673766711 0.05837655 0
4 0.23741363 -0.050535412 -0.0473024899 0.36152575 0.001088718 -0.15354050 0
2 0.48927513 -0.307561385 0.3177238885 0.42054668 0.072770343 0.33271737 0
B3 0.09839211 0.827176406 -0.3244875053 0.44579006 0.159991098 -0.14678016 0
B3 -0.06807770 0.593601657 0.1224855617 -0.10677452 0.351707470 0.53486376 0
9 0.20651979 -0.272977578 0.8259493668 -0.50212781 -0.041644690 1.27476593 0
8 0.00000000 -0.008315345 0.0008152742 0.00000000 0.043469230 0.29596908 1
7 0.00000000 0.155050387 -0.0068404803 0.00000000 0.314397160 -0.50556877 1
7 0.00000000 -0.008021610 0.0639465277 0.00000000 0.122372337 0.27856790 1
8 0.00000000 -0.070217063 0.2370763279 0.00000000 -0.013168583 0.04034823 1
7 0.00000000 0.469712631 0.0130102656 0.00000000 0.566767608 0.18219645 1
7 0.00000000 0.193749720 -0.0788801623 0.00000000 0.383380004 0.47007644 1
7 0.00000000 0.412273782 -0.1046108759 0.00000000 0.307614552 -0.35552820 1
在玫瑰之后,我没有得到所有身份证。我想获得所有身份证。如果有人知道通过为每个观察值保留ID来处理不平衡数据的其他方法。我不想弄乱ID。我尝试了过度采样,散发采样,smote。但是,没有好的结果。我尝试将ID列转换为因子,但无效。
看答案
如果有人仍然想知道,我最终使用了这种方法。我只想要新的合成观察结果,但是Smote不断减小数据集的大小。希望能帮助到你:
library(DMwR)
library(dplyr)
# df - dataframe you want to use over/undersampling on
df$ID <- seq.int(nrow(df))
df_smote <- DMwR::SMOTE(var ~ ., df, perc.over = 100, k = 5)
sub_df <- subset(df_smote, var == "yes")
final_df <- rbind(df, sub_df)
final_df <- distinct(final_df)
- 创建ID列,以确保行完全相同(不是具有相同功能的观察)
- 将Smote与所需的参数(其中 var 是您的二进制变量)。
- 用 var 一定级别 - 在这种情况下,“是”级别。
- 行将子集绑定到原始数据集。
- 删除Smote中引入的重复项。
- 最终,您最终只有与所需级别的合成观测值超过/不足。
智能推荐
pytorch如何加载本地的数据集(例如MNIST/CIFAR10)
问题说明 由于pytorch首次加载MNIST或CIFAR10数据集时需要去外网下载,下载速度惊人。那么我们可以自己先把数据集下载下来,然后按照以下步骤直接加载本地数据集就行。 加载步骤 首先自己去下载MNIST或CIFAR数据集,存放到本地的某个文件夹中,如下图所示: 将数据集所在的文件夹路径复制下来,粘贴到浏览器中,按回车键打开。 - 在浏览器中打开该路径之后显示如下图: 然后将cifar.p...

SMOTE算法-样本类别不平衡问题
类别不平衡问题 类别不平衡问题,顾名思义,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题。例如逻辑回归即不适合处理类别不平衡问题,例如逻辑回归在欺诈检测问题中,因为绝大多数样本都为正常样本,欺诈样本很少,逻辑回归算法会倾向于把大多数样本判定为正常样本,这样能达到很高的准确率,但是达不到很高的召回率。 &n...

mybatis获取insert之后数据库自动生成的id
需求:使用MyBatis往MySQL数据库中插入一条记录后,需要返回该条记录的自增主键值。 方法:在mapper中指定keyProperty属性,示例如下: 如上所示,我们在insert中指定了keyProperty="id",其中id代表插入的User对象的主键属性。 IUserDao.java 测试类:MybatisTest.java 注意:session.commit()...
无意中发现看书也是一种美
2012年4月25日晚,翻翻自己喜欢的一门语言学习书(python参考手册),无意中发现书中夹着之前的明信片(有一次和同事一起去前门邓丽君音乐生活馆留下来的),感觉学习也是一种美!于是乎拍下这不经意的时刻,哈哈!...

香橙派OrangePi PC Plus开发板连接USB以太网卡测试说明
1) 目前测试过能用的 USB 以太网卡如下所示,其中 RTL8153 USB 千兆网卡插入开 发板的 USB 2.0 Host 接口中测试可以正常使用,但是速率是达不到千兆的,这点请 注意 2) 首先将 USB 网卡插入开发板的 USB 接口中,然后在 USB 网卡中插入网线,确 保网线能正常上网,如果通过 dmesg 命令可以看到下面的 log 信息,说明 USB 网卡...
猜你喜欢
计算机网络基础:Vlan,网关,dns吗,子网掩码等!面试必备!
很多朋友多次问到什么是网关、dns、子网掩码,三层交换机,它们定位的用途;确实,因为网络技术在弱电中确实应用非常广泛,我们平时在 vip 技术群中也是不断的讨论到网关、vlan、三层交换机或子网掩码等问题,今天我们就一起用通俗方式一次性了解清楚。 一、什么是 vlan? VLAN 中文是 “虚拟局域网”。LAN 可以是由少数几台家用计算机构成的网络,也可以是数以百计的计算机...

乐播科技冯森:我为什么不看好Android电视游戏
(乐播科技的三位创始人,从右往左依次为:冯森、廖峰、陈锡华) 电视在家居生活中扮演的角色重新获得了人们的认知,这块屏幕成为巨头们谋划的方向,其中一个属性便是家庭的娱乐中心。但在国内,各种基于Android平台的电视和盒子又面临游戏内容缺乏的窘境。当然,很多人或者团队都在努力着希望完善这个生态系统,但是好像没有那么简单。 另一方面,苹果系统已经是非常成熟的平台,各类iOS游戏的质量也很高。于是,来自...

Java使用阿里云OSS对象存储上传图片
该案例是OSS Java SDK的示例程序,您可以修改endpoint、accessKeyId、accessKeySecret、bucketName后直接运行。 本示例中的并不包括OSS Java SDK的所有功能,详细功能及使用方法,请参看“SDK手册 > Java-SDK”, 链接地址是:https://help.aliyun.com/document_detai...
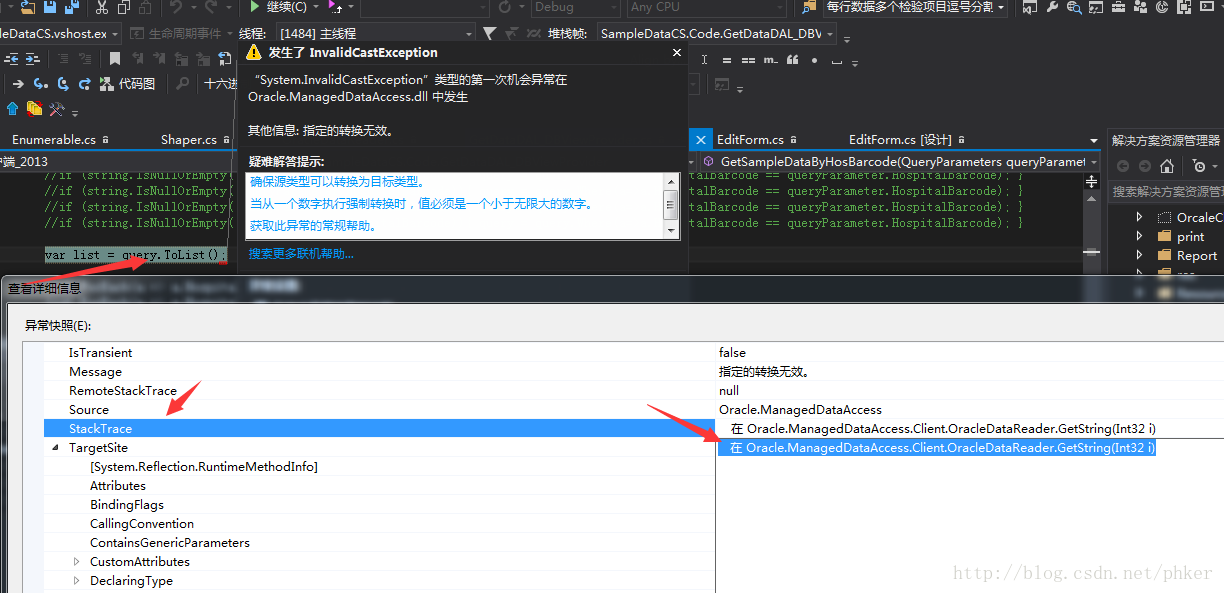
很多.net 程序员不知道又非常重要的 .net高级调试技巧.调试别人的dll方法内的变量...
事情是这样的, 最近需要开发Orcale的数据库. 于是使用了EF 加上 Oracle.ManagedDataAccess.Client 这个Oracle.ManagedDataAccess 很好用, 不需要orcale 客户端就能用. 但是这个类库有个地方不是非常好用. 数据读取出了问题,它的提示非常非常让人气愤. 啥调试信息都没有..只有一个提示 “类型转换异常”. 大...
Spring框架
了解Spring框架 好处 : 1.不依赖于应用服务器. 2.IOC(控制反转)技术实现组件控制. 通过DI(依赖注入)技术提高了组件之间的解耦. 3.通过AOP(面向切面编程)技术实现安全、事务、日志功能的统一管理, 提高复用. 4.Spring框架可以几乎与其他任何框架进行良好的整合使用. 5.Spring所有项目之间不相互依赖. IOC : 控制反转. 本质: 将手动创建对象的工作,交给Sp...
问答精选
How to extract beta coefficients for interaction effect in R?
I am examining the interaction between a continuous variable (bloodq) and a categorical variable with three levels (ER, RB, and WB). In order to see how the betas differ across tissue types, I would l...
what is the difference between Flatten() and GlobalAveragePooling2D() in keras
I want to pass the output of ConvLSTM and Conv2D to a Dense Layer in Keras, what is the difference between using global average pooling and flatten Both is working in my case. That both seem to work d...
How to invoke a test step with inputs at runtime from groovy script in SOAP UI?
I am writing a validation groovy script for a test step, intended to test a SOAP Web Service. Now, I want to call the same test step, with different input value from the groovy script. Is it possible?...
Wicket pagestore results wrong page
I have a problem with my web application with wicket. I am using wicket 6.14. I can't say exactly what the problem is, but I can describe the problem. I am using a self written pagestore, which uses h...
Unity load files from outside of resources folder
In unity is it possible to load a resource that is out side of the resources folder. I want the user to be able to set a textAsset variable from a file outside of the Assets directory entirely. You ca...
相关问题
- 不平衡数据集:Sklearn及以上|下|Smote采样?
- 如何避免为类和它的命名空间具有相同的名称,例如技术。技术?
- 使用DBCC Chertent never的Rose for Rows重置主键是否具有更大的ID
- 在特定时间之后(例如10分钟之后),如何更新Firebase数据库中的值?
- C ++:保留簿记课程的平衡记录
- 如何在Ubuntu上安装Rose Compiler?
- 使用TM函数时保留唯一标识符(例如,记录ID) - 不适用于批次数据?
- 如何在Android Spinner中使用SQLite数据库_ID /值对,同时保留隐藏用户的“_ID”部分?
- Scala Split()之后如何保留元素的顺序
- 错误:未使用的参数使用Smote
相关文章
热门文章
推荐文章
相关标签
推荐问答
- How to Get All Data for Using Linkedin company updates plugin in wordpress
- Is interprocess communication relevant on the iPhone or iPad?
- How to call a function every n milliseconds in "real world" time exactly?
- How to change this regular expression to only match urls?
- Need Help creating GMAIL Pub/Sub Notification service to SpreadsheetApp (Google Appscript)
- Cakephp and moodle on the same server cpanel
- MCUDA installation instructions
- check if circle is at edge of window
- getting HTTP_REFERER in a landing page - brings back the landingpage url
- What happens if I change meta tags after the DOM has materialized?