文本相似度(tf-idf 和 bm25的算法讲解)
1.关于tf-idf:
(使用tf-idf和向量空间模型)
TF: 文档 j 中的关键词 i 的归一化词频值
描述某一词在一篇文档中出现的频繁程度。
(为了阻止更长的文档得到更高的相关度权值,必须进行文档长度的某种归一化)
- TF=freq(i,j) / maxOthers(i,j) ###(maxxOthers = max(freq(z,j))
IDF : 逆文档频率。
降低所有文档中几乎都会出现的关键词的权重。(例如的,了等)
- IDF = log(N /n(i)) ###N 为所有可能推荐文档的数量,n(i)为N中关键词 i 出现过得文档的数量。
TF-IDF权值 = TF*IDF
2.关于BM25:(可插拔的相似度算法)
BM25源于概率相关模型,而非向量空间模型
BM25同样使用词频,逆文档频率以及字段长度归一化,但是每个因子的定义都有细微差别
(###TF-IDF没有考虑词频上限的问题,因为高频停用词已经被移除了)
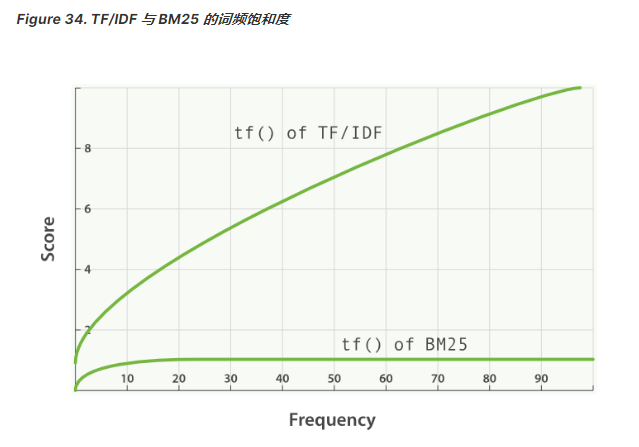
(###BM25 有一个上限,文档里出现5-10次的词会比那些只出现一两次的对相关度有显著影响),参见词频饱和度图:

字段长度的归一化:
字段某个词的频率所带来的重要性会被这个字段长度抵消,但是在实际的评分函数中会将所有字段以同等方式对待,认为所有较短的title 比较长的body 字段更重要。
BM25 当然也认为较短字段应该有更多的权重,但是它会分别考虑每个字段内容的平均长度,这样就能区分短 title 字段和 长 title 字段。
在 查询时权重提升 中,已经说过 title 字段因为其长度比 body 字段 自然 有更高的权重提升值。由于字段长度的差异只能应用于单字段,这种自然的权重提升会在使用 BM25 时消失。
不像 TF/IDF ,BM25 有一个比较好的特性就是它提供了两个可调参数:
这个参数控制着词频结果在词频饱和度中的上升速度。默认值为 1.2 。值越小饱和度变化越快,值越大饱和度变化越慢。
b
这个参数控制着字段长归一值所起的作用, 0.0 会禁用归一化, 1.0 会启用完全归一化。默认值为 0.75 。
在实践中,调试 BM25 是另外一回事, k1 和 b 的默认值适用于绝大多数文档集合,但最优值还是会因为文档集不同而有所区别,为了找到文档集合的最优值,就必须对参数进行反复修改验证。
数学公式:
idf :

tf:

sim = tf*idf
BM25算法代码:
class BM25(object):
def __init__(self, docs):
self.D = len(docs)
self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D
self.docs = docs
self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
self.df = {} # 存储每个词及出现了该词的文档数量
self.idf = {} # 存储每个词的idf值
self.k1 = 1.5 #参数1,默认值是1.2 #####调参就是调这里的啦
self.b = 0.75 #参数1,默认值为0.75
self.init()
def init(self):
for doc in self.docs:
tmp = {}
for word in doc:
tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数
self.f.append(tmp)
for k in tmp.keys():
self.df[k] = self.df.get(k, 0) + 1 #分母+1,平滑处理,避免出现log(0)
for k, v in self.df.items():
self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5) #IDF的计算
def sim(self, doc, index):
score = 0
for word in doc:
if word not in self.f[index]:
continue
d = len(self.docs[index]) #k1
score += (self.idf[word]*self.f[index][word]*(self.k1+1)
/ (self.f[index][word]+self.k1*(1-self.b+self.b*d
/ self.avgdl)))
return score
def simall(self, doc):
scores = []
for index in range(self.D):
score = self.sim(doc, index)
scores.append(score)
return scores
25 公式中包含 3 个自由调节参数 ,除了调节因子 b 外 ,还有针对词频的调节因子 k1和 k2。(我们这里不考虑k2,一般只调节k1)
k1的作用是对查询词在文档中的词频进行调节,如果将 k1设定为 0,则第二部分计算因子成了整数 1,即不考虑词频的因素,退化成了二元独立模型。
如果将 k1设定为较大值, 则第二部分计算因子基本和词频 fi保持线性增长,即放大了词频的权值,根据经验,一般将 k1设定为 1.2。调节因子 k2和 k1的作用类似,不同点在于其是针对查询词中的词频进行调节,一般将这个值设定在 0 到 1000 较大的范围内。之所以如此,是因为查询往往很短,所以不同查询词的词频都很小,词频之间差异不大,较大的调节参数数值设定范围允许对这种差异进行放大。
参考文献: 《Elasticsearch权威指南》中文版-可插拔的相似度算法权威讲解
BM25算法详解具体的公式
在 查询时权重提升 中,已经说过 title 字段因为其长度比 body 字段 自然 有更高的权重提升值。由于字段长度的差异只能应用于单字段,这种自然的权重提升会在使用 BM25 时消失。
来源:网络
智能推荐
文本相似度余弦相似度算法原理
余弦相似度基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。 第一步,预处理主要是进行中文分词和去停用词,分词。 第二步,列出所有的词。 第三步,计算词频。 第四步,写出词频向量。 余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。 余弦相似度缺陷 这类算法没有很好地解决文本数据...
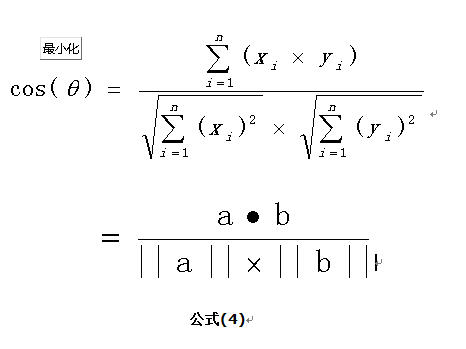
使用余弦相似度算法计算文本相似度
在工作中一直使用余弦相似度算法计算两段文本的相似度和两个用户的相似度。一直弄不明白多维的余弦相似度公式是怎么推导来的。今天终于花费时间把公式推导出来,其实很简单,都是高中学过的知识,只是很多年没用了,都还给老师了。本文还通过一个例子演示如果使用余弦相似度计算两段文本的相似度。 余弦函数在三角形中的计算公式为: 在直角坐标系中,向量表示的三角形的余弦函数是怎么样的呢?下图中向量a用坐标(x1,y1)...

文本相似度的衡量之余弦相似度
余弦计算相似度度量 相似度度量(Similarity),即计算个体间的相似程度,相似度度量的值越小,说明个体间相似度越小,相似度的值越大说明个体差异越大。 对于多个不同的文本或者短文本对话消息要来计算他们之间的相似度如何,一个好的做法就是将这些文本中词语,映射到向量空间,形成文本中文字和向量数据的映射关系,通过计算几个或者多个不同的向量的差异的大小,来计算文本的相似度。下面介绍一个详细成熟的向量空...
神经网络检索方法与一种结合local和distributed文本相似度算法
神经网络检索方法与一种结合local和distributed文本相似度算法 by joeyqzhou 基于频次的信息检索方法 信息检索(IR), 简单说,就是给一个query, 返回与其最相关的doc. 传统的IR方法有tfidf, BM25, 它们主要考虑的是query中词语的确定性匹配(不能匹配到类似词)。即词在某篇候选doc中出现的次数(term frequency)和在所有doc中出现的频...
文本相似度算法:文本向量化+距离公式
1. 文本向量化 1.1 词袋模型 词袋模型,顾名思义,就是将文本视为一个 “装满词的袋子” ,袋子里的词语是随便摆放的,没有顺序和语义之分。 1.1.1 词袋模型的步骤 第一步:构造词典 根据语料库,把所有的词都提取出来,编上序号 第二步:独热编码,D维向量 记词典大小为D,那么每个文章就是一个D维向量:每个位置上的数字表示对应编号的词在该文章中出现的次数。 1.1.2 ...
猜你喜欢
BM25相似度与余弦相似度的对比
在进一步讨论相关度和评分之前,我们会以一个更高级的话题结束本章节的内容:可插拔的相似度算法(Pluggable Similarity Algorithms)。 Elasticsearch 将 实用评分算法 作为默认相似度算法,它也能够支持其他的一些算法,这些算法可以参考 相似度模块 文档。 Okapi BM25 能与 TF/IDF 和向量空间模型媲美的就是&...

文本相似度Levenshtein算法原理(转载)
Levenshtein算法原理 1) str1或str2的长度为0返回另一个字符串的长度。 if(str1.length==0) return str2.length; if(str2.length==0) return str1.length; 2)初始化(n+1)*(m+1)的矩阵d,并让第一行和列的值从0开始增长。 3)扫描两字符串(n*m级的),如果:str1 == str2[j],用te...
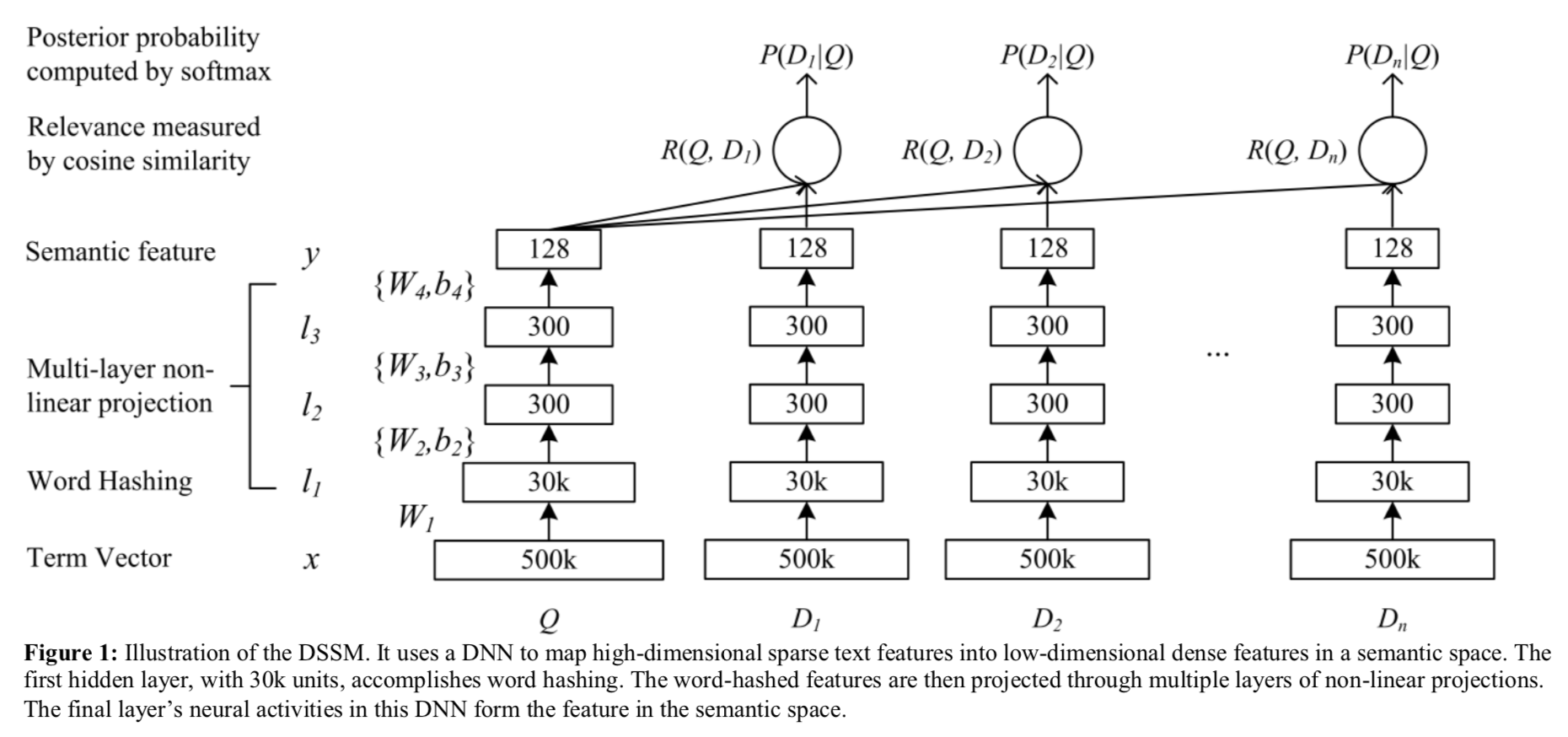
3. 文本相似度计算-DSSM算法
1. 文本相似度计算-文本向量化 2. 文本相似度计算-距离的度量 3. 文本相似度计算-DSSM算法 4. 文本相似度计算-CNN-DSSM算法 1. 前言 最近在学习文本相似度的计算,前面两篇文章分别介绍了文本的向量化和文本的距离度量,这两篇文章的思路主要在机器学习的框架下面,本文准备换一个思路,从深度学习的角度来处理文本相似度的问题。 本文介绍DSSM(Deep Structured Sem...

TexMaker使用教程和相关配置
每次使用TexMaker进行论文写作时,不免需要进行多次配置,下面进行简单的介绍,如何使用TexMaker进行论文写作。 1.TexMaker+MikTex联合使用 TekMaker需要结合MikTex一起使用,如果只下载安装了TexMaker是不会进行成功编译论文的,必须要结合编译器使用,编译器一般有MikTex和Texlive,我使用的是MikTex+TexMaker,首先下载安装MikTex...
artTemplate写法小案例之百度搜索引擎
前篇文章介绍了artTemplate相关使用的知识,这篇主要介绍artTemplate的两个常用方法: 1.template(‘search’,data); 第一个参数是script标签的id名 第二个参数是要传入的数据 2.template.compile() 案例及代码: 1.template(‘search’,data);实现 2.templa...
问答精选
if... else if javascript
I am doing a form validation and having troubles with my code: The first IF statement works and displays the massage if the field is empty, but the ELSE IF for some reason does not... What am I doing ...
Can an included PHP file know where it was included from?
For example, This is index.php Can header.php know it was included by index.php? --EDIT-- I found a solution: header.php While $_SERVER['PHP_SELF'] will contain the currently executing script, there i...
Match escaped html in regex c#
How can I escape html codes in Regex? I need to find the string in a string like I can not use HtmlEncode/Decode for this purpose cause i need work with tags. That i want i just find the common string...
Function to multiply 3x3 matrices gives wrong answer for middle column only
While teaching myself c, I thought it would be good practice to write a function which multiplies two 3x3 matrices and then make it more general. The function seems to calculate the correct result for...
Openstack Kilo dashboard forward
I've setup the Kilo in LAN, which can't be accessed by the external network. Now, I'd like to do a forwarding to make it be accessed from outside. How to set the ProxyPass and ProxyPassReverse? I aske...
相关问题
相关文章
热门文章
推荐文章
相关标签
推荐问答
- How to count frequency of elements by row of entire table
- XAML Setter Property to Command
- ValueError: invalid width 0 (must be > 0)
- Obtaining Polynomial Regression Stats in Numpy
- How to enable https for a dev environment on Angular app
- Submitting a php table with input boxes
- XSD - Enumeration restricted values that can be empty
- How to Email sending in android
- Comparing type when you have a System.Type
- Numpy polyfit and numpy polynomial