机器学习案例系列教程——优化方法总结(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)
梯度下降法
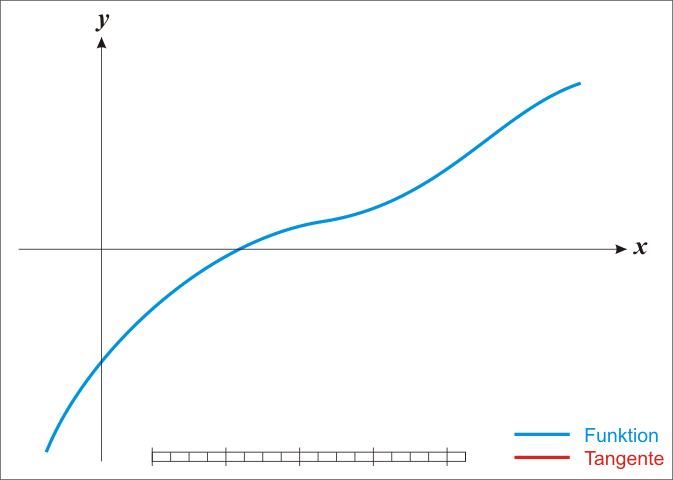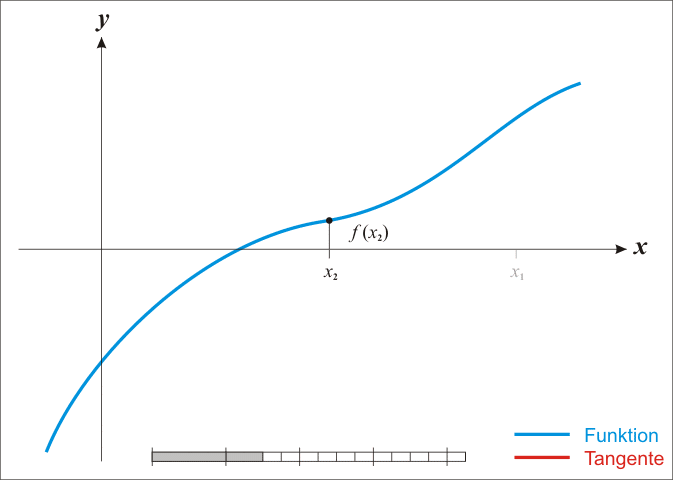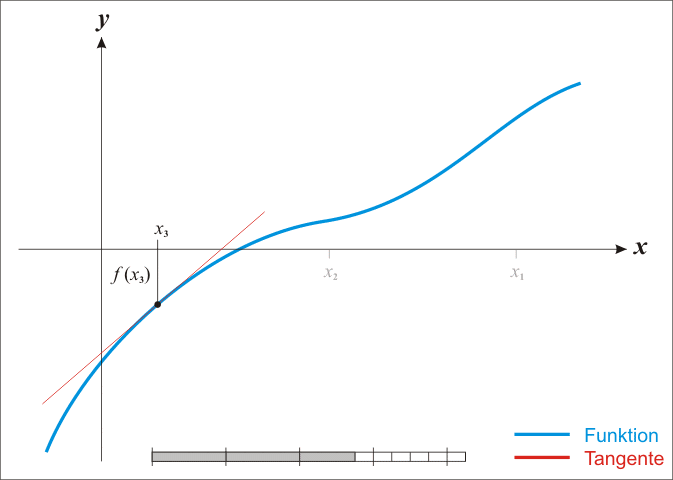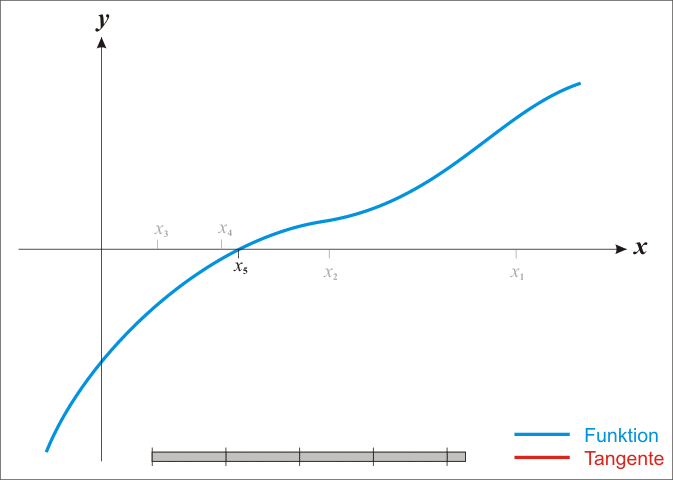
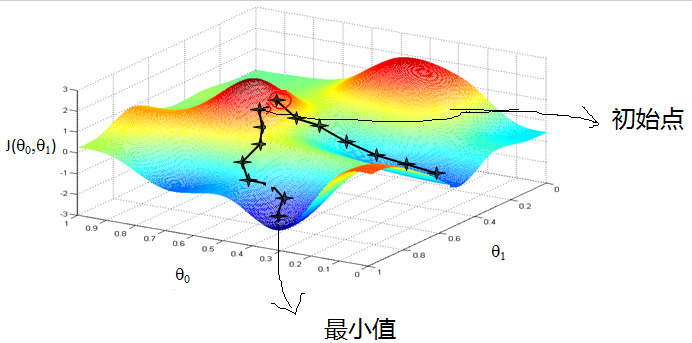
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:
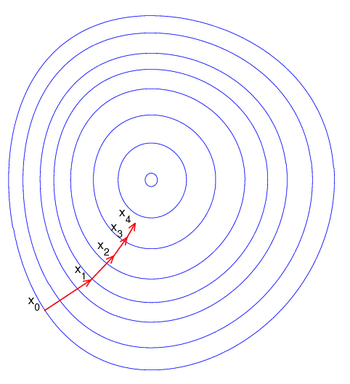
梯度下降法的缺点:
(1)靠近极小值时收敛速度减慢,如下图所示;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降。
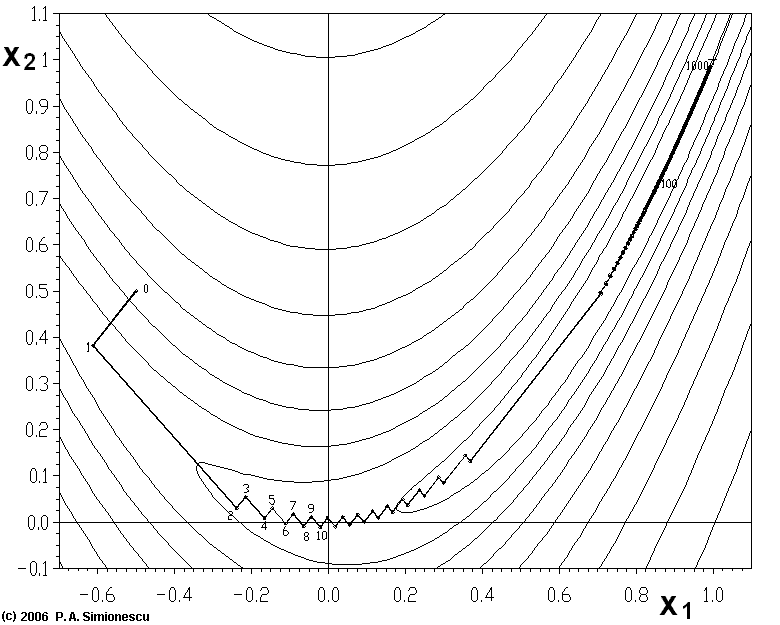
从上图可以看出,梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
比如对一个线性回归(Linear Logistics)模型,假设下面的h(x)是要拟合的函数,J(theta)为损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的样本个数,n是特征的个数。
1)批量梯度下降法(Batch Gradient Descent,BGD)
(1)将J(theta)对theta求偏导,得到每个theta对应的的梯度:
(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta:
(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度会相当的慢。所以,这就引入了另外一种方法——随机梯度下降。
对于批量梯度下降法,样本个数m,x为n维向量,一次迭代需要把m个样本全部带入计算,迭代一次计算量为。
2)随机梯度下降(Stochastic Gradient Descent,SGD)
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:
(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta:
(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
随机梯度下降每次迭代只使用一个样本,迭代一次计算量为n2,当样本个数m很大的时候,随机梯度下降迭代一次的速度要远高于批量梯度下降方法。两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
对批量梯度下降法和随机梯度下降法的总结:
批量梯度下降—最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降—最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
上面我们学习了梯度下降法,下面我们来反过来学习下梯度下降法为什么是下降最快的方法。
假设为第次迭代的损失函数值
其中为脚步方向,也就是一个单位长度的向量。λ是步长,为步幅。公式进行泰勒展开,只取一阶导数,后面的省略。则要尽可能大,所以要尽可能小,其中和都是向量,两个向量内积运算最小。则两个方向相反。所以是的方向的单位向量。
牛顿法
上面的梯度下降法,我们知道了是一次求导,走的是每次下降最快的方向,看的也是当前一步下降最快的方向,但是这样找的只是局部最优点,并不是全局最优点。
仍然延续上面的公式
牛顿法保留到泰勒展开的二次导。牛顿法最大的特点就在于它的收敛速度很快。
其中为Hesse矩阵(二阶导数矩阵)。其中为第t次迭代的值,为下一次更新的值,也就是要求的未知值。
对求导,并令其等于0,得
假设的逆矩阵存在,则
具体步骤:
首先,选择一个接近函数 零点的 ,计算相应的 和切线斜率(这里表示函数 的导数)。然后我们计算穿过点并且斜率为的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
我们将新求得的点的 x 坐标命名为,通常会比更接近方程的解。因此我们现在可以利用开始下一轮迭代。迭代公式可化简为如下所示:
已经证明,如果是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。下图为一个牛顿法执行过程的例子。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是”切线法”。牛顿法的搜索路径(二维情况)如下图所示:
牛顿法搜索动态示例图:
关于牛顿法和梯度下降法的效率对比:
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
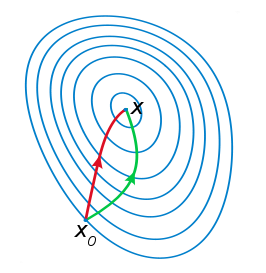
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
拟牛顿法
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
启发式优化方法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
还有一种特殊的优化算法被称之多目标优化算法,它主要针对同时优化多个目标(两个及两个以上)的优化问题,这方面比较经典的算法有NSGAII算法、MOEA/D算法以及人工免疫算法等。
解决约束优化问题——拉格朗日乘数法
参考:https://blog.csdn.net/luanpeng825485697/article/details/78823919
来源:网络
智能推荐

牛顿法,梯度下降法,拟牛顿法
牛顿法,梯度下降法,拟牛顿法。 梯度下降法的推倒(https://blog.csdn.net/pengchengliu/article/details/80932232) 顺带提一嘴,最小二乘法其实也就是MSE。 牛顿法其实就是对函数进行二阶泰勒展开求极值的问题,最后得到的是递推关系x与函数一阶导和二阶导的关系。 其中H代表黑塞矩阵,也就是函数的二阶偏导数矩阵,g代表函数的一阶导数矩阵。下面是具体...

最优化方法——最速下降法,阻尼牛顿法,共轭梯度法
最优化方法——最速下降法,阻尼牛顿法,共轭梯度法 目录 最优化方法——最速下降法,阻尼牛顿法,共轭梯度法 1、不精确一维搜素 1.1 Wolfe-Powell 准则 2、不精确一维搜索算法计算步骤 3、最速下降法 3.1 基本思想 ...

数学优化入门:梯度下降法、牛顿法、共轭梯度法
1、基本概念 1.1 方向导数 1.2 梯度的概念 如果考虑z=f(x,y)描绘的是一座在点(x,y)的高度为f(x,y)的山。那么,某一点的梯度方向是在该点坡度最陡的方向,而梯度的大小告诉我们坡度到底有多陡。 对于含有n个变量的标量函数,其梯度表示为 1.3 梯度与方向导数 函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。 1.4 梯...
实用优化算法总结——0.618法、梯度下降、牛顿法、共轭梯度、外罚、内罚
实用优化算法总结 实用优化算法的种类繁多,并且各自使用的领域有所区别,为此,设计有多种优化算法,本文着重介绍其中几种,见目录。 如有需要,matlab版代码会后期放出来 最优化问题,可以分为两大部分“无约束最优化问题”和“约束最优化问题”。 目录 实用优化算法总结 无约束最优化问题 黄金分割法 最速下降法 牛顿法 基本牛顿法 阻尼牛顿法 LM方法:克...
八、梯度下降法和拟牛顿法
1、梯度 2、梯度上升和梯度下降 3、梯度下降算法详解 3.1 直观解释 3.2 梯度下降相关概念 3.3 梯度下降的矩阵描述 3.4 梯度下降的算法调优 4、梯度下降法大家族 5、梯度下降法和其他无约束优化算法的比较 July解释 6、拟牛顿法 6.1 牛顿法 6.2 拟牛顿法 1、梯度 梯度下降经典总结 微积分里边,对多元函数求偏导数,把求得的各个参数的偏导数以向量的形式写出来就是梯度。 对函...
猜你喜欢

梯度下降法,最速下降法,牛顿法,Levenberg-Marquardt 修正,共轭方向法,共轭梯度法
优化对象:凸函数 梯度下降法 顾名思义,就是沿着与梯度相反的方向迭代。(梯度方向是增长最快的方向,所以负梯度方向是下降最快的方向)。 最速下降法 最速下降法是梯度方向法的一种,与上面的梯度下降法不同的是:梯度下降法是固定的学习率,最速下降法是变化的学习率(具体见下面的介绍)。 特点:每一次迭代时的梯度方向与上一次迭代时的梯度方向正交 牛顿法 在某一个特定点处将函数泰勒展开(仅保留至二次项),用泰勒...

梯度下降、牛顿法和拟牛顿法
1. 梯度下降法 梯度下降法用来求解目标函数的极值。这个极值是给定模型给定数据之后在参数空间中搜索找到的。迭代过程为: 可以看出,梯度下降法更新参数的方式为目标函数在当前参数取值下的梯度值,前面再加上一个步长控制参数alpha。梯度下降法通常用一个三维图来展示,迭代过程就好像在不断地下坡,最终到达坡底。为了更形象地理解,也为了和牛顿法比较,这里我用一个二维图来表示: 懒得画图了直接用这个展示一下。...
Blender 插件之 Blender for UE4
Blender 插件之 Blender for UE4 https://zhuanlan.zhihu.com/p/146665394 Blender 插件之 Blender for UE4 WeArt微创意 腾讯科技有限公司 游戏美术 怎么使用? 使用Blender处理虚幻引擎4的对象包可能很繁琐。这就是为什么我创建加载项:“ Blende...

widows版本oraclexe的安装副本
1.安装好了在crm命令行里输入: sqlplus system/密码 看到如下提示就证明安装成功: 还有一种连接是基于网络通过监听器来完成连接的: 输入:sqlplus system/密码@127.0.0.1:1521/xe 2.继续来配置plsq Developer 进去之后在工具一栏选择:首选项 在其目录下配置路径如下: 连接成功之后以system的权限去登录,并且可以创建用户,...

Flink基础 -- 2.Flink的安装和第一个Demo
Flink的安装 Flink的相关安装步骤如下: 装虚拟机 装系统 装jdk 装scala(不需要不用) 装Hadoop(不需要不用) 装Flink 配置环境变量 如果只是刚开始的自我测试,安装还是很简单的,直接下载包,上传服务器,tar解压,配置了环境变量,source一下,ok,可以用了,这时不放start-cluster.sh一下启动flink吧(这里只是测试,安装了...
问答精选
How to create spinner in wicket
I am looking for spinner in wicket which should be simillar as JSpinner in java swing. I found class: http://www.jarvana.com/jarvana/view/org/wicketstuff/minis/1.4.9/minis-1.4.9-javadoc.jar!/org/wicke...
Selecting individual elements on mouse click HTML
I am trying to implement selecting individual elements on the click of the mouse in a html page. When clicking, I want to be able to find which element I am clicking on. The end goal is to be able to ...
How to get time from server in android?
Possible Duplicate: Does anyone know of a good JSON time server? Is there any public json or xml present on server which I can parse for current time? I shall use this time for checking the expiration...
Wildcard table matches with _TABLE_SUFFIX and sub-query
The _TABLE_SUFFIX feature is great and exactly what I was looking for to solve my problem - however it is scanning all of the data matched by the wildcard when I use a sub-query to determine which tab...
SQL order by DATE DESC + group on other Column
I have tried a lot of different grouping and ordering syntax but I am really struggling to get what I need. I am trying to order by DATE DESC, but I also want the PROJECTS to stick together (no matter...
相关问题
相关文章
热门文章
推荐文章
- 超过10的带圆圈的自动项目编号
- Eclipse:Maven配置packaging为war报错
- CUDA8.0 + VS2015 + Win7 64 + VAssistX
- spring boot 连接postgreSQL,注入过程中的错误
- SAP中采购订单中的汇率是如何确定的
- PowerDesigner V16.5 安装教程以及汉化(数据库建模)
- 痞子衡嵌入式:为下一代智能可穿戴设备而生 - i.MXRT500
- 打开idea后 本来正常使用的Gradle 却报错了 gradle\native\19\windows-amd64\native-platform.dll.lock (拒绝访问)
- Jmeter&Ant构建自动化测试平台
- 应用程序如何实现高级量规界面自定义?这个第三方控件很好用
相关标签
推荐问答
- adding a second outer query in a subquery
- Jquery - if url has _edit in the link then dont show a div else show
- Relative screens in titanium apps
- Python: printing result of multiple inputs
- webmatrix - sql query using DateTime.Now
- What is practiced in C++ to use for byte manipulation uint8 or char?
- access file of the calling folder from Azure DevOps pipeline template
- What is a Memory Safety Vulnerability?
- Image And Text Glitch In Wordpress
- JS scroll page to location by height