基于jieba分词的TF-IDF提取关键词算法中自定义所使用逆向文件频率(IDF)的文本语料库

自行编写TF-IDF算法和Jieba中TF-IDF算法结果比较
任务:对10个战略新兴产业描述文档提取特征词,从而建立10个产业的特征,要求是10个产业特征词区分度和代表度越大越好。采用TF-IDF算法对文档提取特征词,一开始使用jieba自带tf-idf算法,结果不太理想,见下图,每一列为10个产业提取的特征词,红色是之间有重复的情况。 分析原因:jieba的tf-idf算法tf值和idf值依托自身的词典,所以没有针对性。 自己编写TF-IDF算法,效果
TF-IDF算法
TF-IDF算法 某个词的TF-IDF值就越大,说明该词对文章的重要性越高,越有可能成为关键词。 TF(Term Frequency)词频 IDF(Inverse Document Frequency)逆文档频率 IDF大小与一个词的常见程度成反比 TF-IDF的计算

文本挖掘预处理之TF-IDF
频率成反比。 TF——词频:一个词在文章中出现的次数。 在计算词频时,需要注意停用词的过滤。什么是停用词:在文章中出现次数最多的“的”、“是”、“在”等最常用词,但对结果毫无帮助,必须过滤的词。 TF计算有两种方式,具体公式如下: IDF——反文档频率:一个词在所有文章中出现的频率

达观杯数据竞赛项目--提取TF-IDF特征(Date2)
成正比,但也会随着其在语料库中出现的频率成反比,例如词汇 你,我,她,的 等,这类词汇称为停用词。所以说TF-IDF是一种基于bag-of-word的方法。TF-IDF的主要思想就是寻找在该文档中出现.../100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在

【python 走进NLP】关键词提取的几个方法
总结一下:主要有2种提取方法 1. 关键词匹配 在一个已有的关键词库中匹配几个词语作为这篇文档的关键词。可用AC自动机算法等。 2. 关键词提取 通过算法分析,提取文档中一些词语作为关键词。可用tf-idf算法,textrank 算法等 一个简单的demo: 运行结果:
智能推荐
机器学习-nlp-sklearn进行关键词提取(基于tfidf)
背景 tfidf相对词频可以很好的反应出文本中的关键词。本文将使用sklearn进行关键词提取。 实战 结巴分词 使用pandas读取csv文件内容 遍历titile内容进行分词 加载停用词 遍历进行停词 使用sklearn的TfidfVectorizer对文本进行向量化 tfidf.toarray()转换成为矩阵,然后进行行排序,取最后的n个索引(argsort是拿到索引值) 通过get_fea...

hanlp提取文本关键词的使用方法记录
本文是csu_zipple 分享的关于使用hanlp汉语言处理包提取关键词的过程一个简单的记录分享。想要使用hanlp提取文本关键词的新手朋友们可以参考学习一下! 如何在一段文本之中提取出相应的关键词呢? 之前有想过用机器学习的方法来进行词法分析,但是在项目中测试时正确率不够。于是这时候便有了 HanLP-汉语言处理包 来进行提取关键词的想法。 下载:.jar ...

TF-IDF与余弦相似性的应用(一):自动提取关键词
这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。 有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到? 这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以...
TF-IDF与余弦相似性的应用(一):自动提取关键词
转自:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html 这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。 有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到? 这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的...
TF-IDF与余弦相似性的应用(一):自动提取关键词
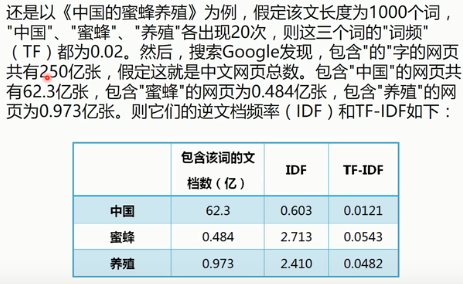
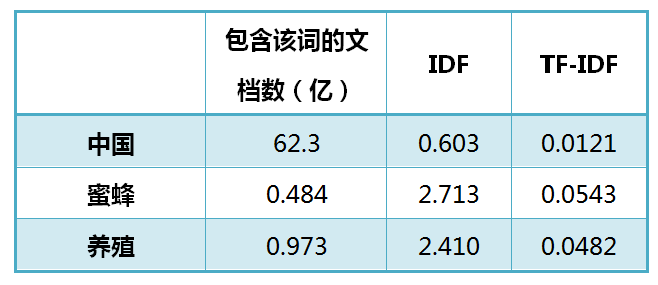
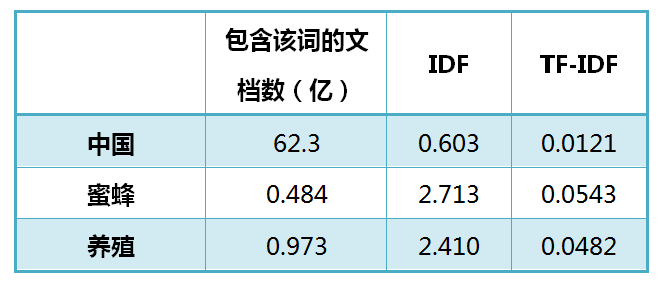
这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。 让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。 ...
猜你喜欢
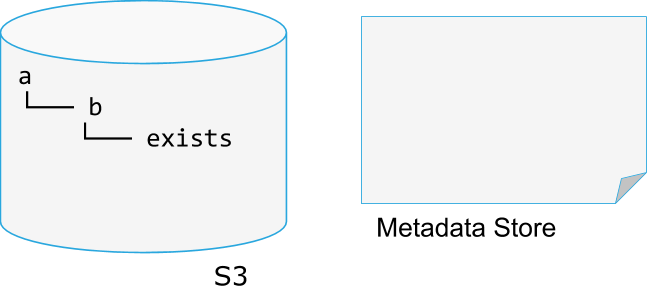
AWS S3存储基于Hadoop之上的一致性保证
前言 Hadoop发展至今,它所涵盖的周边生态圈已经非常庞大了。但是作为一套目前看来如此成熟的系统,免不了要做一些兼容性的事情,比如一些第三方服务类型的系统。毕竟有些用户会使用到第三方的系统,但又不想去改变现有程序运行的模式以及学习第三方系统的成本。Hadoop作为一个如此成熟的项目,在兼容其它第三方系统上,肯定是有考虑到。今天,笔者就来讲讲目前Amazon S3服务与Hadoop的集成兼容性问题...
matlab支持向量机
关于支持向量机(SVM)的一个简单应用实例及matlab代码 (2014-04-23 10:32:35) 转载▼ 分类: 信号处理 ******************************************************** ****************************************************...
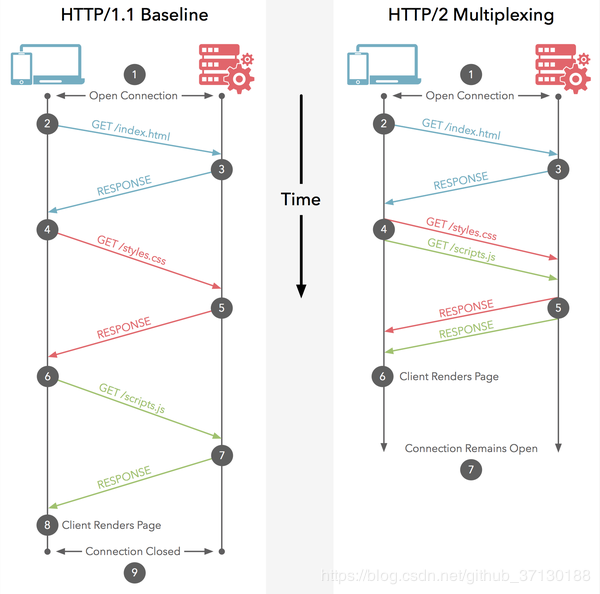
HTTP2.0和HTTP1.X相比的新特性
1.新的二进制格式(Binary Format): HTTP1.x的解析是基于文本。(文本的表现形式有多样性,要考虑的场景很多才能做到健壮性) 基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。 2.HTTP2.0比HTTP1.0有路复用(MultiPlexing): 即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可...
概念的完整性
定义 概念的完整性,是指针对于一个领域,不仅了解该领域的所有对象,并且了解所有对象之间的关系。比如,小学数学中的四则运算。所有的对象就是指有理数,所有的关系就是由加减乘除四种运算而能够产生另外一个有理数。如果对这样的计算完全了解的话,那么使用这样的领域来解决问题就不成问题。 人月神话 概念的完整性在一本20年了还是非常深刻的软件工程书中被重点提出。这本书叫...

Docker ELK+Filebeat安装与配置 并用spring data elasticsearch连接 (遇到的问题服务器内存小太,elasticsearch太新)
Linux版本: Centos 7 Docker安装 yum install docker 启用服务 systemctl start docker systemctl enable docker 关于ELK ELK实际上是Elasticsearch+Logstash+Kibana的缩写,关于三个组件的详细介绍,请自己查看各大网站文章,这里就不再描述。 最近都在研究Docke...
问答精选
How is the workflow/ sequence of the JS: compare function to an array?
I know that's function: is fully working for sorting array contain number in ascending.. If the result is negative a is sorted before b. If the result is positive b is sorted before a. If the result i...
How to use javascript variable out of the scope?
I am using $.get functionality to get json data from action method. But out of $.get() function JavaScript variable getting default value. code look like: Output display look like: And then Display 0....
XMLSchema validation for StAX parser
In DOM or SAX parsers in Java it is possible to define the XML Schema to use by calling methods DocumentBuilderFactory.setSchema(..) or SAXParserFactory.setSchema(...). How can I do the similar thing ...
java.lang.NoSuchFieldError: IBM_JAVA for a simple hbase java client in Eclipse
As the title goes.My source code is: It seems that this error has nothing to do with hbase server because I can use hbase shell properly. But I really don't konw how to fix this problem.Both from my L...
Postgres: convert a list of "name=value" values into a table
Convert this string: using something like this (in Postgres 9.x): to get a result like this: PS: I can't create any function, so I need to use Postgres built in functions only. Thanks in advance. stri...
相关问题
相关文章
热门文章
推荐文章
- vue 列表渲染
- 手机里同时放电信卡和联通卡诡异情况描述
- 数据库之 MongoDB and SQLite
- express : 无法加载文件 C:\Users\50817\AppData\Roaming\npm\express.ps1,因为在此系统上禁 止运行脚本。有关详细信息,请参阅 https:/go
- docker的安装以及mysql安装测试
- 自制后台网页
- 机器学习(二十三)——常见算法(关联、相似、TF-IDF等)
- reGeorg+proxifier+proxychains工具将主机代理进入内网
- Intellij idea 报错:Error : java 不支持发行版本5
- Linux系统的运行模式简介
相关标签
推荐问答
- How to read only 5 last line of the text file in PHP?
- how to save data of an activity when accidental crash occurs
- Are there ways to specify the conversion character for double and float in C without having to know the number of its decimal?
- which technology to choose to create a web chat client?
- Asynchronous Python CGI call halts browser until complete
- Font anti-aliasing for labels in Xcode 4
- Need to add/update the arguments of an durable rabbitmq queue
- Angular2 - how to dynamic insert the component that were created?
- Add in-app purchase with parse.com
- Flattening MultiIndex pivot table in Python pandas